别学我突击。。。
Chaper0-1:数值型数据的表示
各种码是什么
真值:用正、负符号加绝对值表示数值
机器数:计算机 内部的用二进制数码来表示数的表示方法。
原码:符号位 + 真值的绝对值的二进制。(+-0)
反码:正数反码与原码相同。负数原码的符号位不变,其余各位按位取反.(+-0)
补码:正数补码与原码相同。负数其反码的末位加 1。
移码:给原码加上一定的固定偏移量()
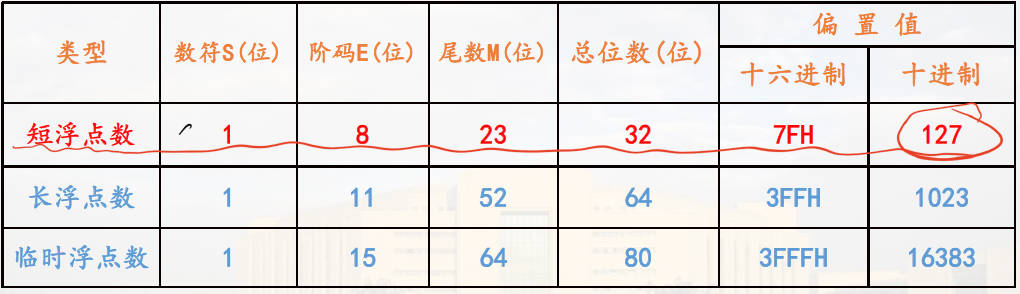
IEEE754表示方法:
$$ N = (-1)^{S}\times{M}\times R^{E} $$其中,S 是符号位,M 是尾数,R 是阶权,E 是阶码。
但是在存储中,存储的是 S,f(规格化后为1.xxxx乘后面的,此处的 f 只记录小数点后的部分),e=E+bias。bias = 二次方的阶码的存储位数减一。eg.短浮点数bias= $2^{8}-1=127$
转换方法
确定符号位、将绝对值转为二进制、规格化二进制数(表达成$N=(-1)^{S} \times 1.f \times R^{e - bias}$)、组合各部分(S,f,e)。
一个例子:
特殊 ASCLL 码:0->30 A->41 a->61(注意此处都是16进制表示)
Chaper0-2:数字逻辑基础知识
离散数学基础知识,没学好的有福了……这里好像就一个新的加法分配律:A+BC=(A+B)(A+C)
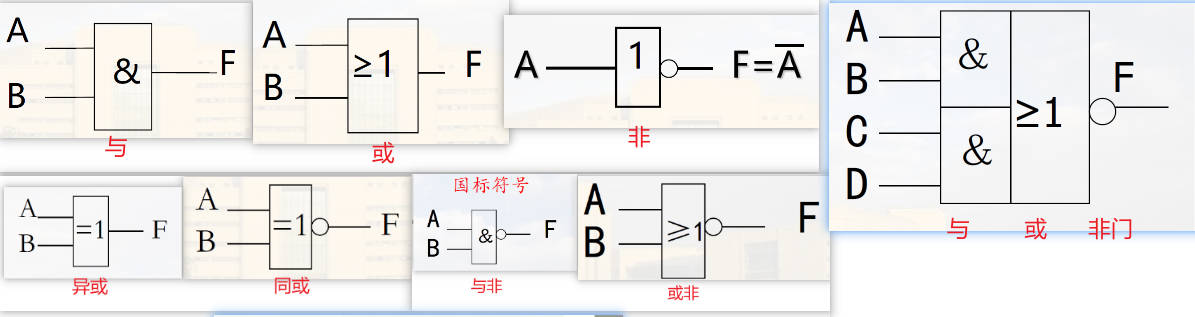
各种门的图像表示
组合逻辑电路
特点:电路由逻辑门构成,无记忆元件。输入信号是单向传输,一般无反馈。
分析方式:逻辑电路图转换成函数表达式,再化简,可以得到真值表,描述功能。
有个视频可以迅速了解一下下面的东西
半加器&全加器
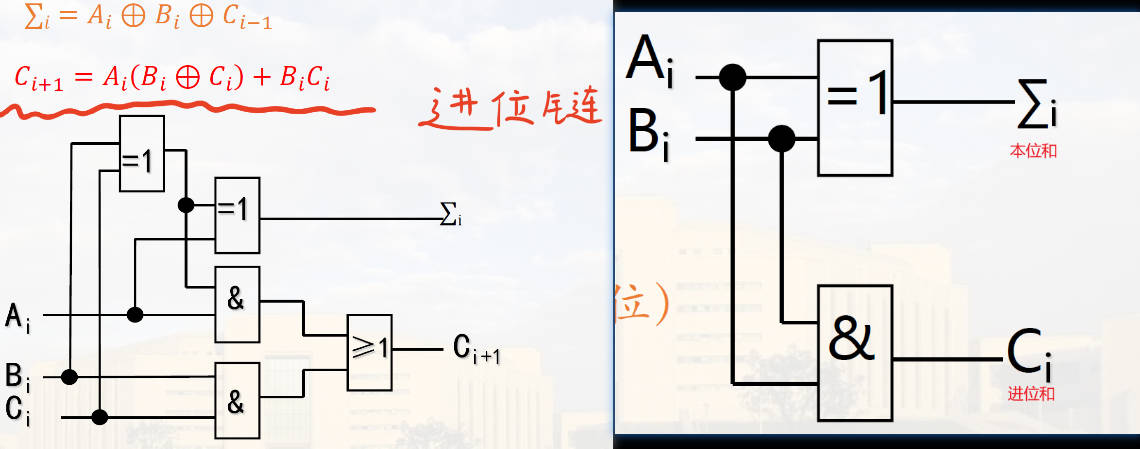
推导过程:列出真值表,写出最小项,然后用公式对最小项的和进行化简。
编码器
所谓编码,就是在选定的一系列二值代码中赋予每个代码以固定的含义。执行编码功能的电路称编码器
典例:低电平8-3编码器:对为0的那一位进行编码,第n位,就编码成二进制表示的n。
然后可以更细致地,写出每一位的逻辑表达式。例如:
$$Y_2 = I_4 + I_5 + I_6 + I_7 = \overline{\overline{I_4} \space \overline{I_5} \space \overline{I_6} \space \overline{I_7}}$$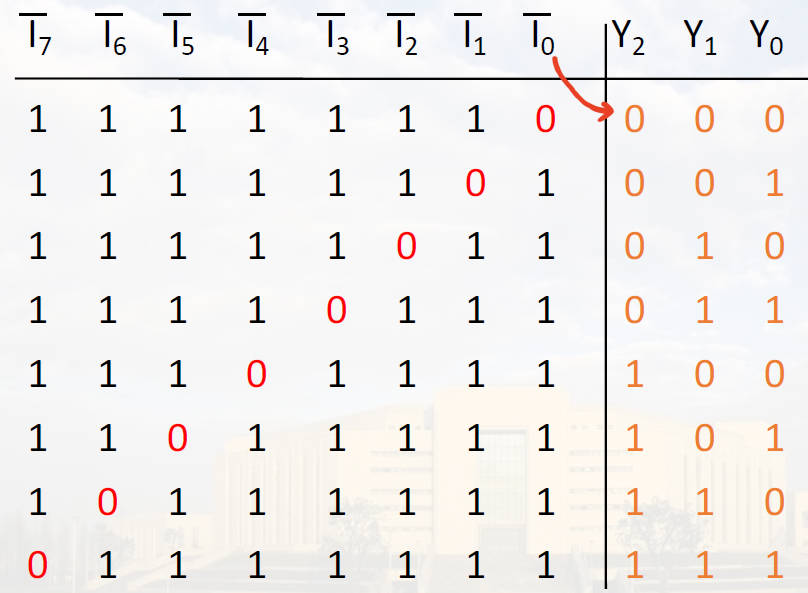
译码器
将具有特定含义的不同二进制代码“翻译”出来。
二进制译码器属于完全译码器(设译码器有 n 个输入和 m 个输出,则 $m=2^{n}$),不满足该条件的称为部分译码器。
其实就是编码器的逆过程,但是多了一个 E 工作开关(使能端,还可以用于译码器的扩展),如果 E = 0 那么后面的输出就是全 0 或者全 1。
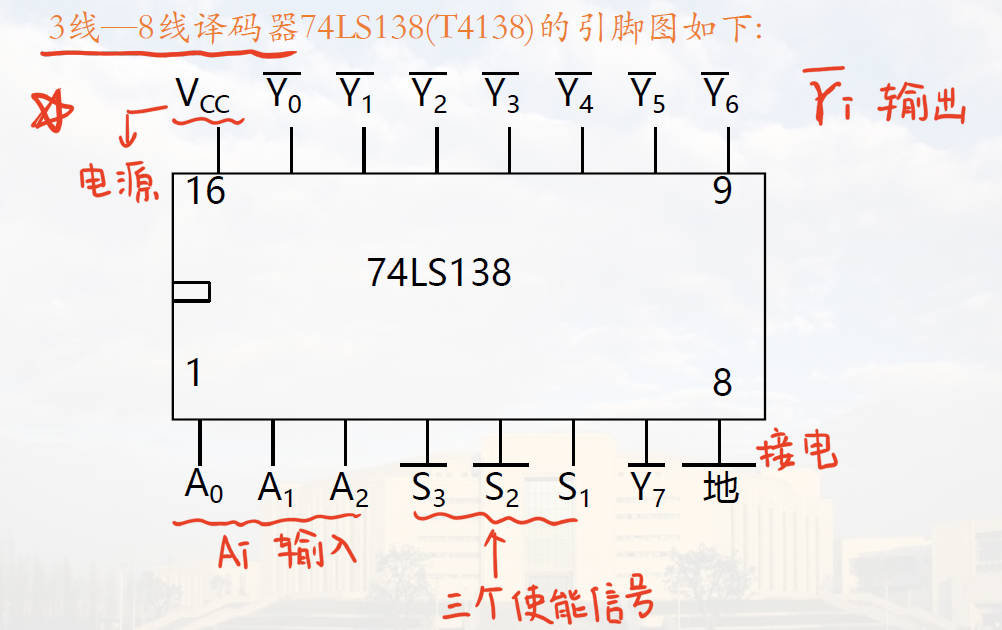
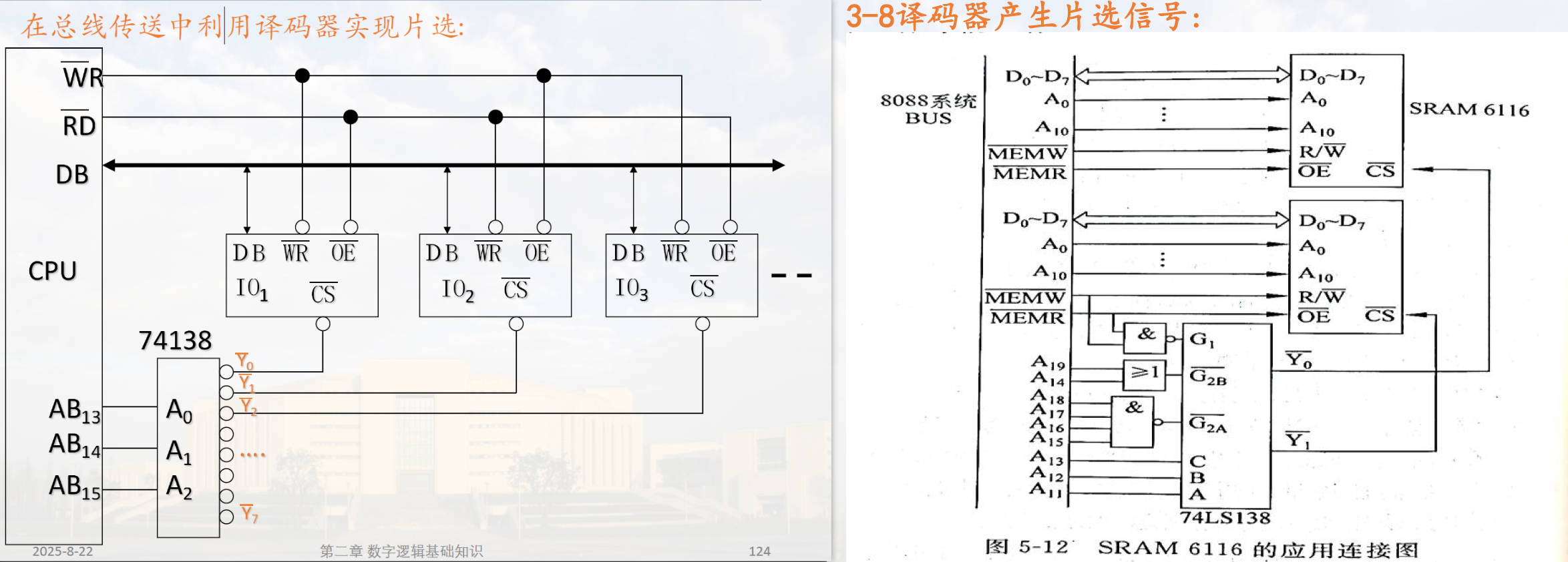
物理电路如下图所示:

推导方式:先列出真值表,计算每一位的解码逻辑表达式,然后再对需要译码的进行取反再取反,中途&末尾导出正反,进一步进行利用。
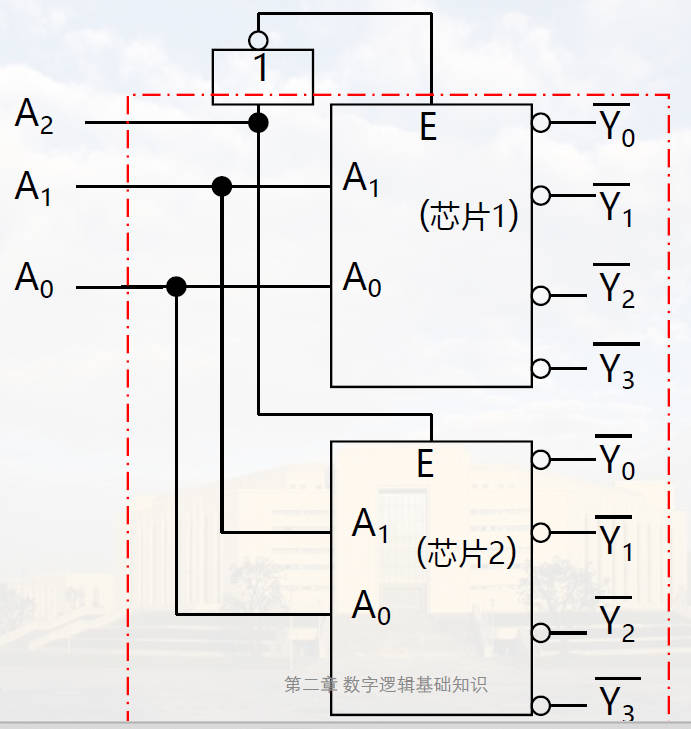
两片 2-4 译码器组合成一片 3-8 译码器。首先把 8 位分成前四位和后四位,后四位当且仅当 3 位输入最高位不为 0 的时候才可能用到,因此可以拿最高位当作下面那一片的使能端。同时两片只有一个能在工作状态,因此注意到 A2 其实用作控制信息。
时序逻辑电路
实际上是组合逻辑电路+存储电路的组合。
电路由组合电路和存储电路组成,具有对过去输入进行记忆的功能;电路中包含反馈回路,通过反馈使电路功能与“时序”相关;电路的输出由电路当时的输入和态(对过去输入的记忆)共同决定
触发器
能够存储一位二进制信息的基本单元电路称触发器。特点是:具有两个能自我保持的稳定状态,且具有一对互补输出。有一组控制(激励、驱动)输入(使能信号)。具有现态(接受输入之前的状态 $Q_n$)与次态(接受输入之后的状态 $Q_{n+1}$)
分为无 cp (基本 R-S 触发器)与有 cp 的触发器(钟控 RS 触发器、D 触发器、维持阻塞 D 触发器、集成 D 触发器)
集成 D 触发器
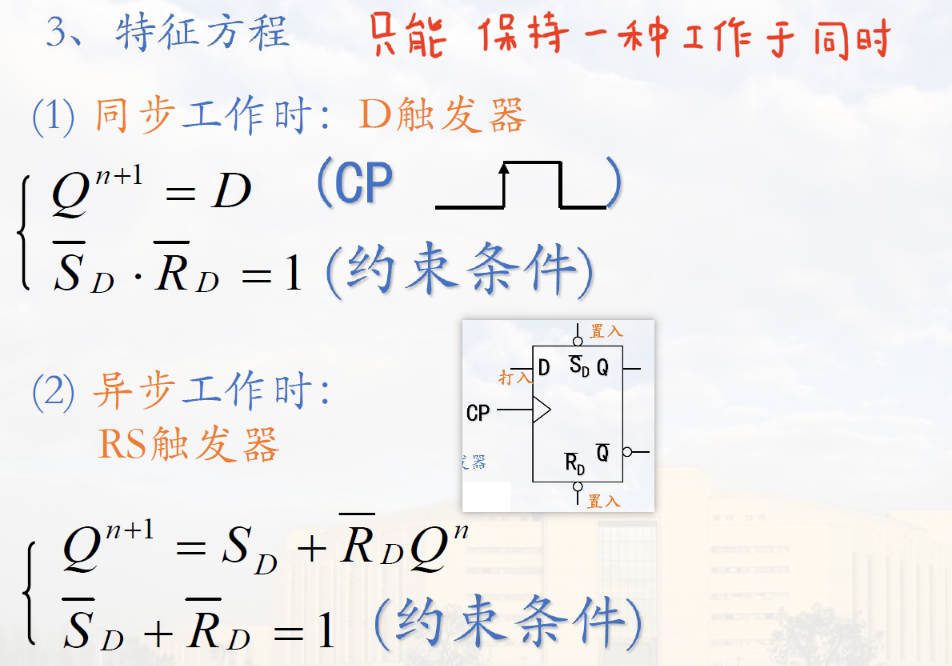
特点:“D 与状态一致”、边沿触发更新。
Chapter 1-1 系统组成部分
基本组成:CPU (运算器、控制器)、存储器、输入设备、输出设备。存储时,代码都已成指令。工作流程:编写程序 - 输入程序 - 存储程序 - 程序转换为指令序列 - 执行指令 - 输出结果。
两大流:控制流 & 数据流。
存储程序方式:事先编制程序 - 存储程序 - 自动连续运行程序的工作方式
冯诺依曼体制:采用二进制形式表示数据和指令、采用存储程序方式工作、由五大部分组成计算机系统的硬件、传统的诺依曼机串行执行指令(后增加并行处理功能)。
电平信号+一组总线实现并行操作,脉冲信号+一条总线实现串行操作。
能在程序控制下自动连续的工作的原因是 PC 寄存器(program counter)
主要功能部件
CPU
运算器(ALU 为核心) + 控制器
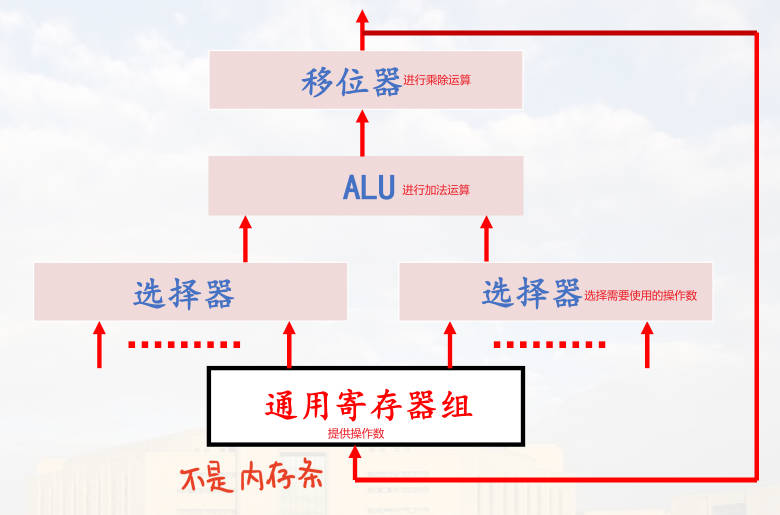
控制器产生控制命令(微命令)控制全机操作。下图为更完整的结构。ppt 上是只展示了微命令发生器收到指令信息、状态信息、时序信号。
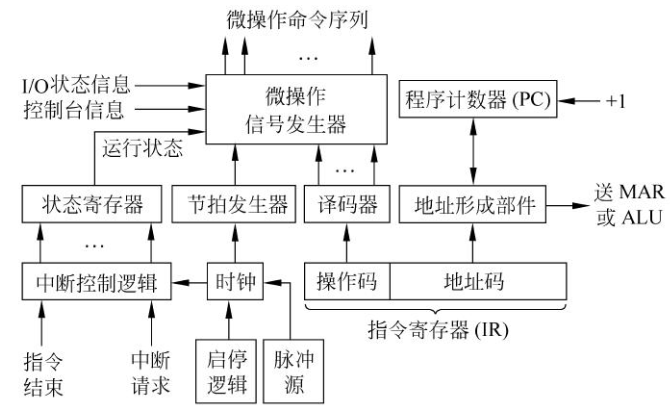
微命令产生方式(指令执行控制方式):组合逻辑电路产生微命令、微指令产生微命令,分别对应组合逻辑控制方式和微程序控制方式。
两种控制器的组成原理&控制机制、模型及的数据通路结构和指令执行过程后附(挖坑)
存储器
存储信息。寻址系统选择存储单元,通过控制线路产生读写时序,控制读写操作,右侧完成读写操作,暂存读写的数据。
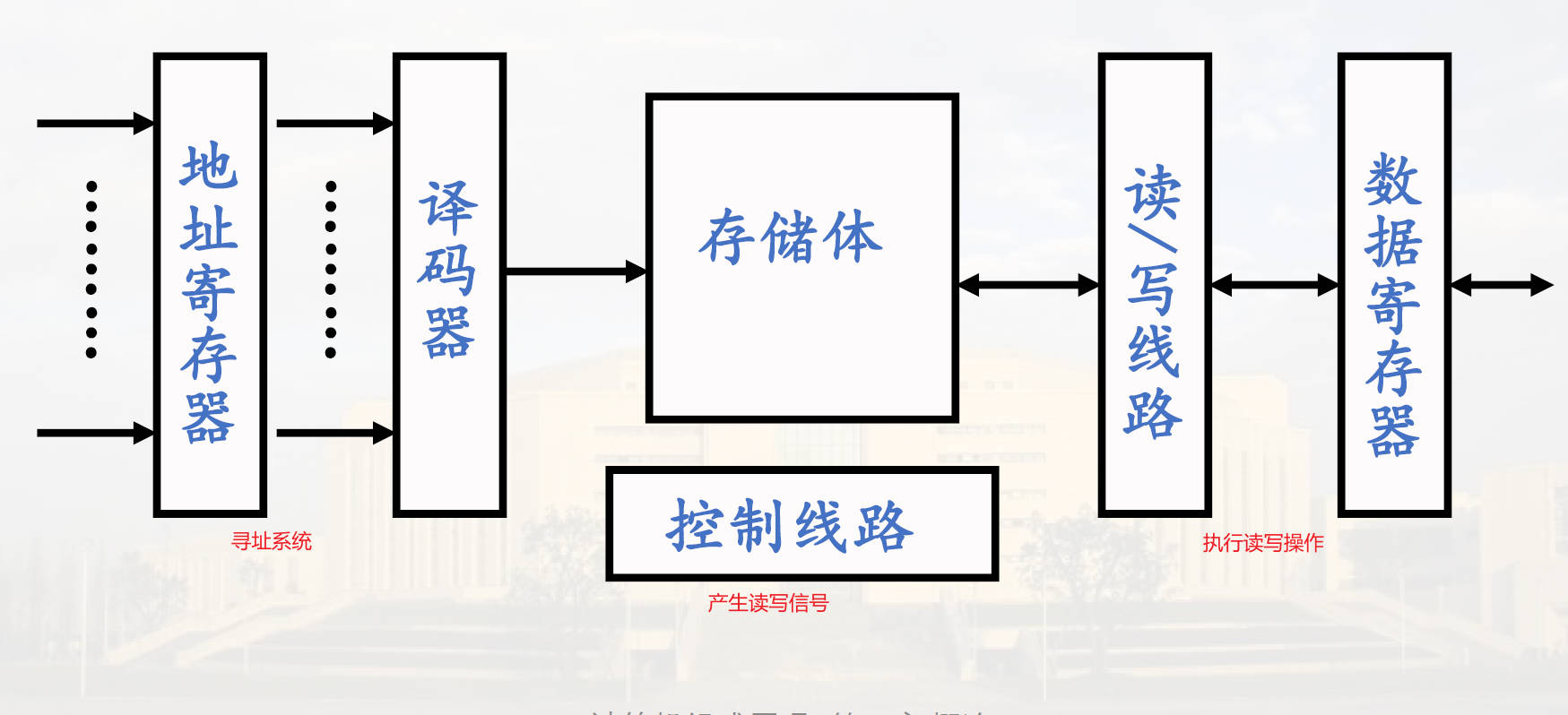
存储单元读/写原理、存储器逻辑设计后附(挖坑)
输入输出设备
转换信息。
显示器的工作原理和信息转换过程(挖坑)
接口
部件与部件(指硬件或软件)之间的交接部分称为接口;主机系统总线与 I/O 设备之间的交接部分称为 I/O 接口。按传送格式分串、并行接口;按时序控制分为同、异步接口;按信息传送控制方式分为中断接口和 DMA 接口。
接口:中断接口、DMA接口(挖坑)
Chapter 1-2 硬件系统结构
总线:能为多个部件分时、共享的一组信息传送线路及相应的控制逻辑。按功能分为内外、局部系统总线;按传送信息分为地址(AB)、数据、控制(CB)总线;按格式分为并、串行总线;按时序分为同步、异步总线;按方向分为单、双向总线。
以总线为基础的系统架构
-
以 CPU 为中心的双总线结构:
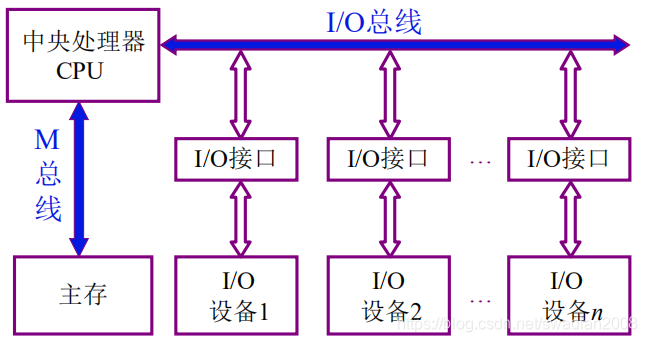
-
单总线结构:(一条杆子上挂一堆东西)
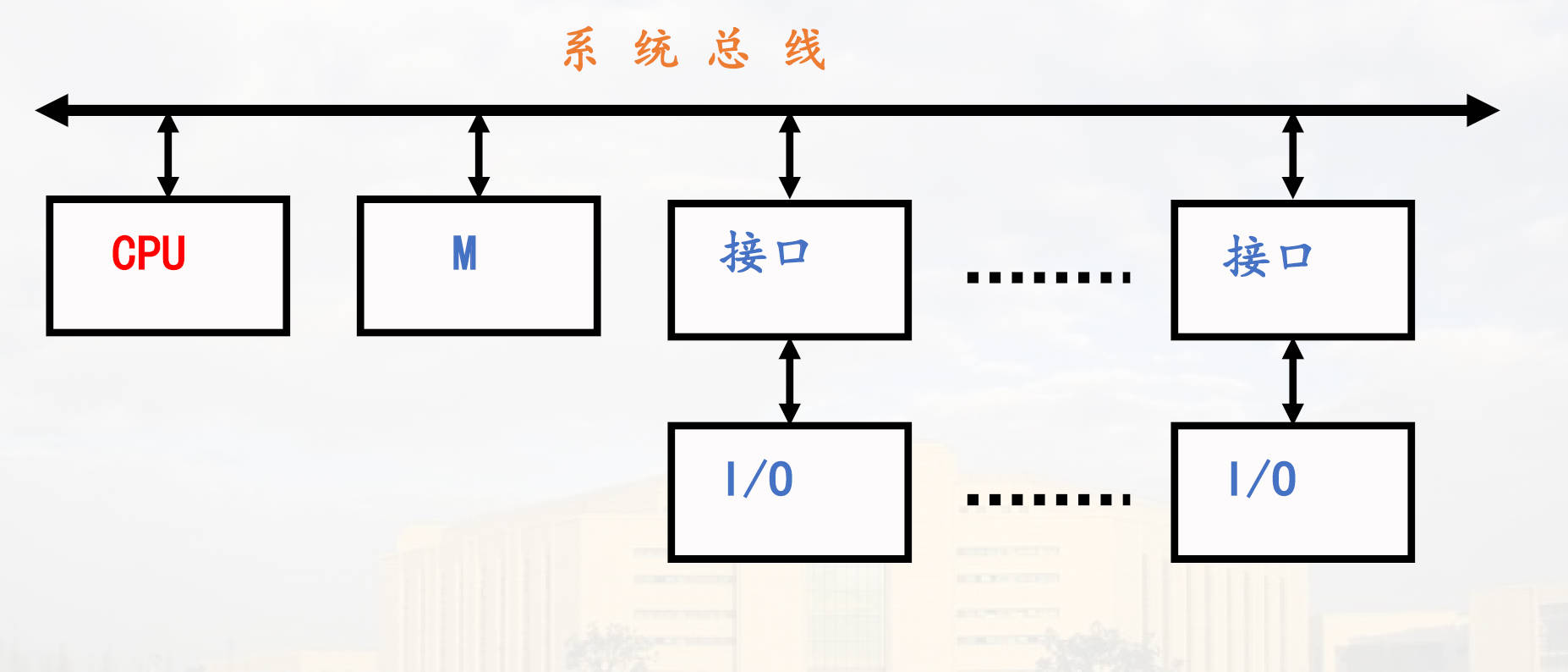
-
以主存为中心的双总线结构

-
多级总线结构
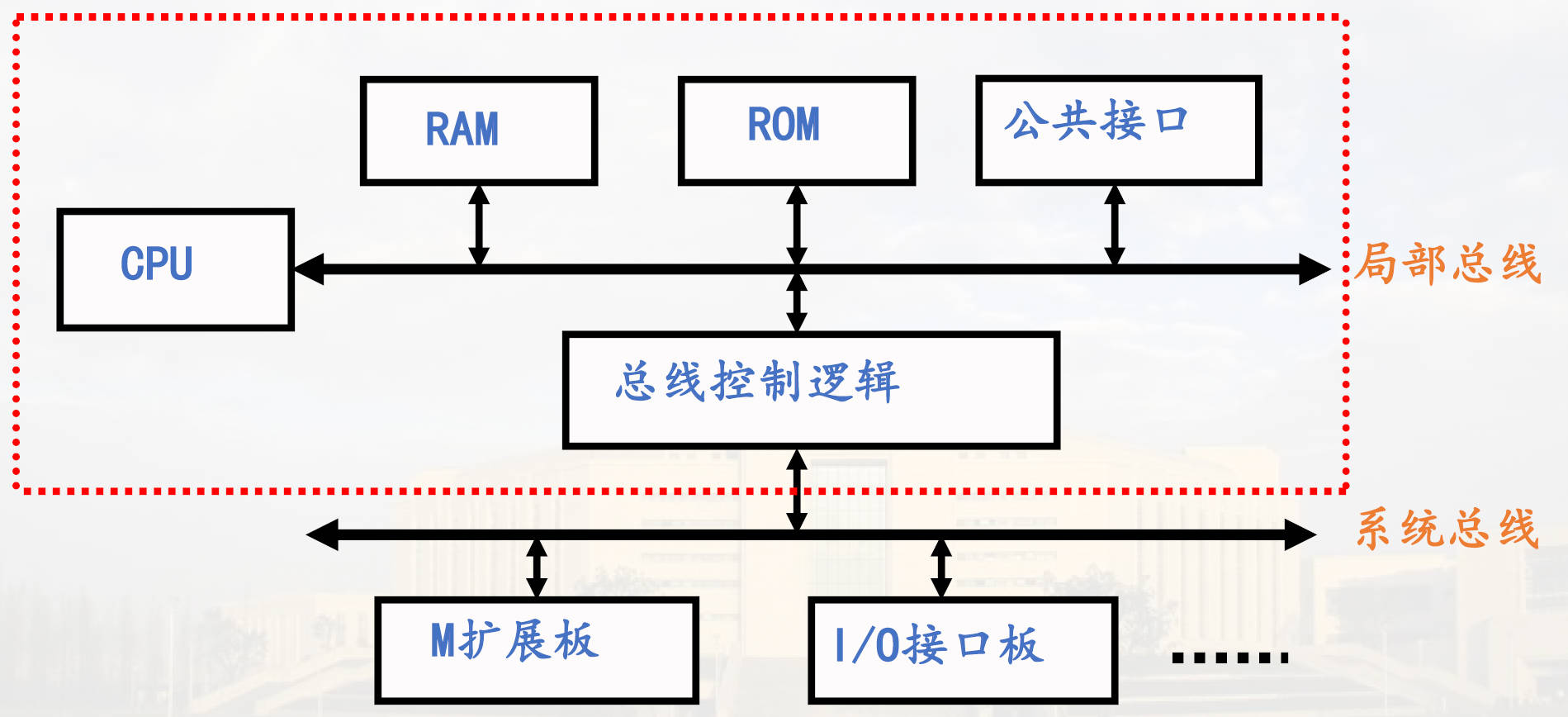
采用通道或IOP的大型系统结构
-
带通道的系统

-
带 IOP 的系统( Input/Output Processor ):

模型机系统架构采用单总线结构。
总线:分类、信号组成(挖坑)
计算机系统的性能指标
-
基本字长:指参加一次定点运算的操作数的位数
-
运算速度:考虑 CPU 主频 & 时钟频率。CPU 主频指计算机的振荡器输出的脉冲序列的频率,是一切操作的时间基准信号。时钟频率是主频脉冲经分频后所成的时钟脉冲序列的频率,两个相邻时钟脉冲之间的间隔时间是一个时钟周期时间,也称为节拍。
-
数据通路宽度:指数据总线(多条)一次能并行传送的数据位数。
-
数据传输率:指数据总线每秒传送的数据量,也称为数据总线的带宽。计算方式是宽度*频率/8,单位是 bit/s 。$B=\frac{W\times f} {8}$
-
存储容量:主存容量 & 外存容量。主存容量:可编址存储单元个数(地址个数)× 位数(编制单元的存储容量)
Chapter 2 指令系统
计算机的工作体现为指令的执行,包含三个步骤:取指(从主存中)、执行指令、存结果。
指令的基本格式
指令格式:操作码(绝对仅 1 个) + 地址码(0、1、2、3)。最基本的指令格式就是这样直接组合。
需要考虑的:指令字长、操作码需要多少位、地址码有几个(隐含了多少个)、寻址方式
指令字长越长:指令功能越丰富,完成工作越多。但是占用存储空间大,从主存中取指时间越长, 指令执行速度越慢。(特别是早期)
操作码
操作码的位数决定了操作类型的多少,位数越多所能表示的操作种类也就越多,有定长(当指令长度比较长时,位置、位数固定,位置在指令的前几位)、扩展(指令长度比较短时,位置、位数不固定,用扩展标志表示)、方式码。
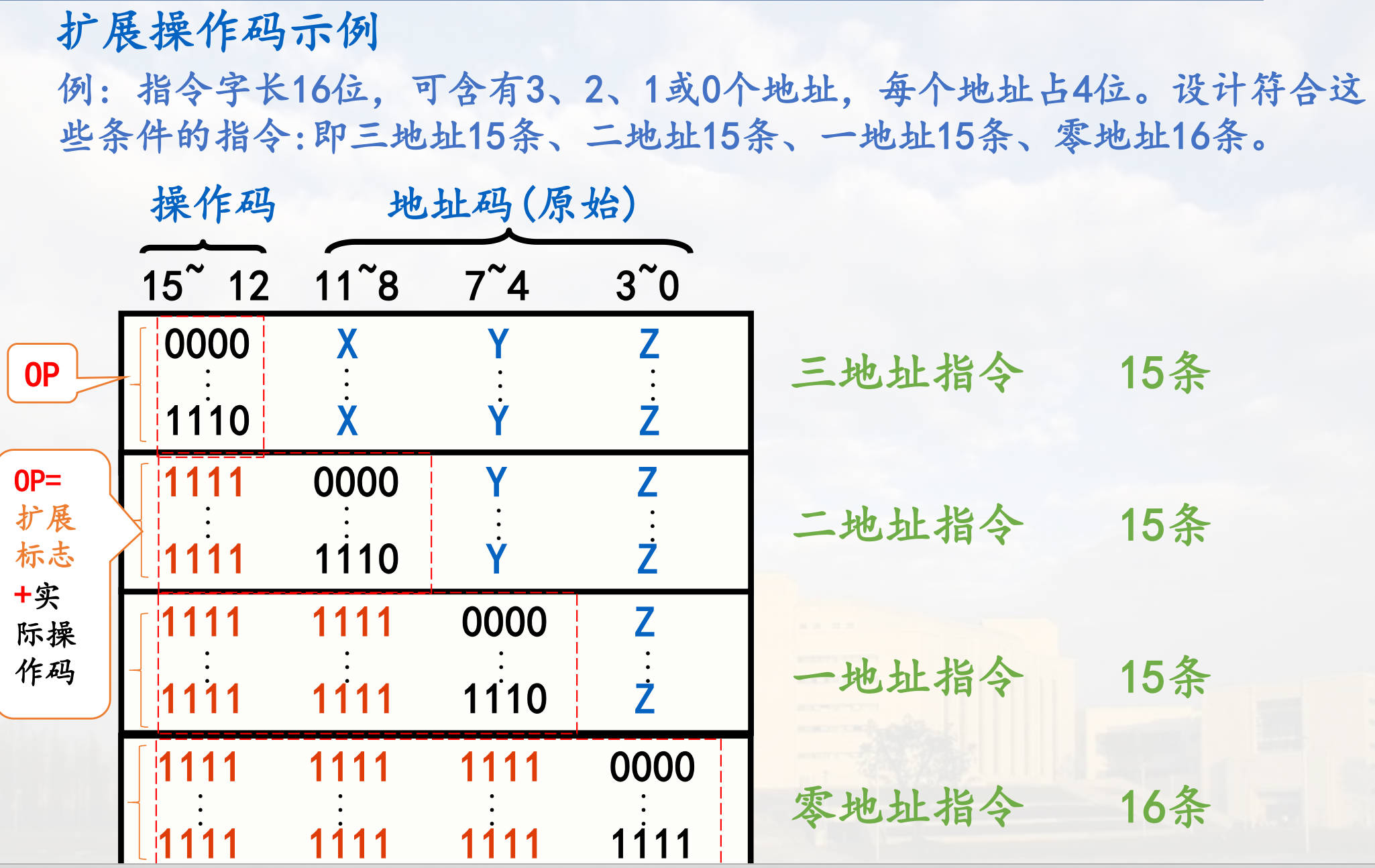
操作数
操作数可以在主存中开辟的软堆栈、CPU 寄存器中的硬堆栈、外设接口中的寄存器、主存/外存中。总结就是 堆栈、寄存器、存储器。
指令给出操作数地址的方式:显式(直接、间接、变址、基址)与隐式(隐含约定寄存器号、主存储单元号)
-
显地址:例如给出主存储单元号或者 CPU 寄存器编号。分为 3、2、1、0地址指令。
-
隐地址:例如系统事先隐含约定操作数在CPU某个寄存器中或是在堆栈中
简化地址结构就是要尽量使用隐地址。
四地址指令
(A1) OP (A2) -> A3, 下条指令-> A4
| OP(操作码) | A1(操作数地址1) | A2(操作数地址2) | A3(结果存放地址) | A4(下一条指令地址) |
|---|
三地址指令
在上一个的基础上,使用隐地址,隐藏下条指令地址,隐藏在 CPU 寄存器 PC 中。下条指令:( PC) + n -> PC,此处令 n = 1。(A1) OP (A2) -> A3
| OP(操作码) | A1(操作数地址1) | A2(操作数地址2) | A3(结果存放地址) |
|---|
二地址指令
在上一个基础上,由于一般操作数用了就不会再用,故把结果放回 A1 or A2中。(A1) OP (A2) -> A1/A2(一般来说,放到第一个操作数中,例如 ADD A1 A2 就放到 A1 里面)
| OP(操作码) | A1(操作数地址1)(一般称为目的操作数) | A2(操作数地址2) |
|---|
一地址指令
分为隐含约定目的地的双操作数指令、只有目的操作数的单操作数指令
| OP(操作码) | A1(操作数地址1) |
|---|
隐含约定目的地的双操作数指令:(A1) OP (AC) -> AC,(PC) + n -> PC。
(OPRD 代表 8 位寄存器)
例如无符号字节(8b)乘法:OPRD×AL→AX(MUL DL 执行的是 DL×AL→AX)
无符号字(16b)乘法OPRD×AX→DX:AX(MUL BX 执行的是 BX×AX→DX:AX)
只有目的操作数的单操作数指令:OP (A1) -> A1。例如求负(NEG BL)、求非(NOT BL)
零地址指令
就一个 OP。分为对只有目的操作数的指令、不需要操作数的指令、对堆栈栈顶单元内容进行操作
对只有目的操作数的指令:
-
PUSHF:FLAGS→堆栈栈顶;POPF ;堆栈栈顶→FLAGS;
-
LAHF :FLAGS的低8位→AH;SAHF :AH→FLAGS的低8位
不需要操作数的指令:NOP :空操作指令;HLT :停机指令
对堆栈栈顶单元内容进行操作:PUSH (压入堆栈)、POP (弹出堆栈)
指令寻址方式
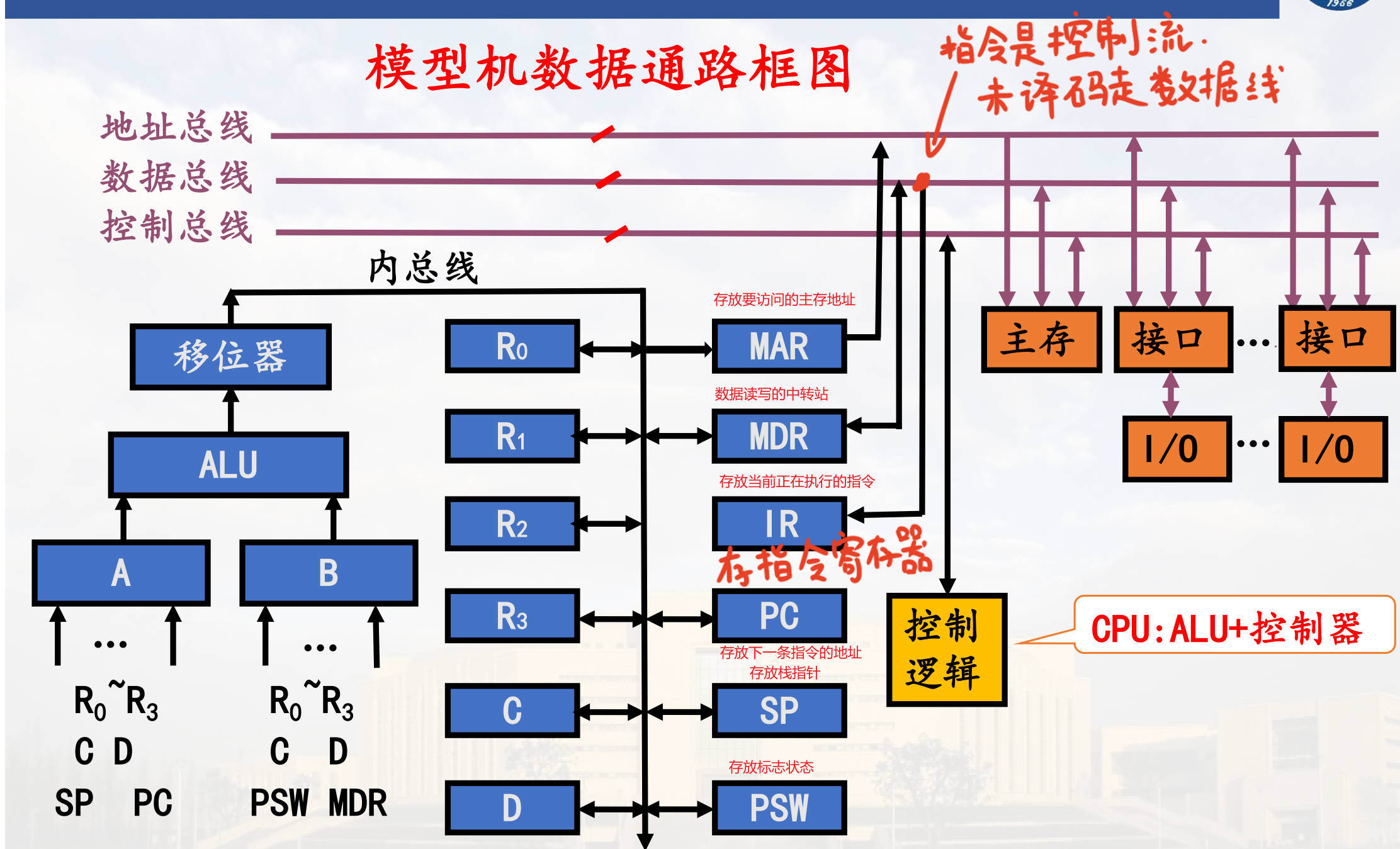
CPU 能直接访问的是寄存器和主存中的操作数。
立即寻址
在读取指令的同时也就从指令之中获得了操作数,即操作数包含在指令中。(操作数此时在IR中)
例如:MOV AX,1234H,就是直接获取可立即使用的操作数(1234H)到 AX 中。
直接寻址
直接给出主存地址或寄存器编号,从主存单元内或CPU的寄存器内读取操作数。给出寄存器数或存储器数。
-
主存直接寻址(慢):地址码是主存的某个单元号,操作数存放在该指定的主存单元中。例如:MOV AX,[2000H]
-
寄存器直接寻址:地址码是CPU内某寄存器编号,操作数存放在该指定的寄存器(可编址寄存器)中。例如:MOV AX,BX
模型机中寄存器编号:R0=000,R1=001,R2=010,R3=011,SP=100,PSW=101,PC=111
间接寻址
先从某寄存器/主存中读取地址,再按这个地址访问主存以读取操作数。
若操作数地址存放在另一主存单元之中(不是由指令直接给出),则该主存单元被称为间址单元,间址单元本身的地址被称为操作数地址的地址。
在间址单元的存储内容(一般选择最高位)中设置一位间址标志位,1 代表是间址,0 代表有效地址。
堆栈有向上、向下、固定生长方式。此处采用向上(但是 x86 是向下),假设栈底初始值为00FFH
-
主存间接寻址(助记符 M):地址给出的是间址单元地址,从中读取操作数地址,按照操作数地址再次访问主存,从相应单元中读写操作数。
-
寄存器间接寻址(助记符 R):地址码是CPU的寄存器编码,被指定的寄存器中存放的是操作数地址,按照该地址访问主存某单元,该单元的内容为操作数
-
自增型寄存器间址方式(助记符:(R)+):在上面的基础上,多执行了一个 R = R + 1
-
自减型寄存器间址方式(助记符:(R)-):在第二个基础上,多执行了一个 R = R - 1
-
堆栈寻址:操作数在堆栈中,指令隐含约定由堆栈指针SP寄存器提供栈顶单元地址。分为两个操作:压栈 & 出栈。
-
压栈:
寄存器号$\xrightarrow{SP}$ 操作数地址=(SP)-1 $\xrightarrow{M}$ 操作数S
操作数S与寄存器SP的关系为:S=((SP) - 1)
-
出栈:
寄存器号 $\xrightarrow{SP}$ 操作数地址 $\xrightarrow{M}$ 操作数S
操作数S与寄存器SP的关系为:S=((SP))
-
变址类
变址寻址
指令给出的是形式地址(不是最终地址),经过某种变换(例如相加、相减、高低位地址拼接等),才获得有效地址,据此访问主存以读取操作数。助记符:X(R)
变址寻址方式的目的是为了灵活修改地址以适应连续区间(程序循环)的操作。
给出变址寄存器号和一个形式地址,变址寄存器的内容(称为变址量)与形式地址相加,得到操作数有效地址(即操作数实际地址),按照有效地址访问某主存单元,该单元的内容即为操作数。
其中 S 为操作数,Rx 为指令给出的寄存器号,D 为形式地址,N 为变址量
$S=((Rx)+D)=(N+D)$
基址寻址
指令中给出基址寄存器号和一个形式地址,基址寄存器内容(作为基准地址)与形式地址(作为位移量)相加,其和为操作数有效地址(即操作数实际地址),按照该地址访问主存储器,该单元的内容即为操作数,这种寻址方式称为基址寻址。(在8086/8088中使用BX(隐含使用DS段)、BP(隐含使用SS 段))
基址寻址方式的目的是扩大有限字长指令的寻址空间,
基址加变址方式:同时获得两个目的。
指令类型
按指令格式分为双操作数指令、单操作数指令、程序转移指令等。
按操作数寻址方式分类: RR型(寄存器—寄存器型) RX型(寄存器—变址存储器型) RS型(寄存器—存储器型) SI型(存储器—立即数型) SS型(存储器—存储器型
按指令功能分为:传送指令 输入/输出(I/O)指令 算术运算指令 逻辑运算指令 程序控制类指令 处理机控制类指令等
一般传送指令 MOV
将数据从一个位置(源地址)传送到另一个位置(目的地址)。
需要说明:传送范围、传送单位、寻址方式 传送范围:允许数据在什么范围内传送。主要是在主存和寄存器之间。
1)CPU寄存器之间的数据传送 :MOV Rj Ri ,即Ri→Rj。一般来说,省略了 [Ri],毕竟传送的是数据。传送必定经过一次 CPU。
2)主存储器单元之间的数据传送:MOV mem2,mem1,但是没有这个指令,因为时序长度不够。这个过程很复杂,需要 Ri 中转。
3)从CPU寄存器传送到主存单元: MOV mem,reg,即Ri→M。这个有些用助记符 STORE 表示。
4)从主存单元传送到CPU寄存器:MOV reg ,mem,即M→Rj。这个有些用助记符 LOAD 表示。
传送单位:数据可以按字节、字、双字或数组为单位进行传送。所以应当指明。
设置寻址方式。
堆栈指令:就是出栈和压栈。如果栈在主存上,可以视为存储、读出主存数据的特例。
数据交换指令:XCHG AX,BX
实际上采用了一个暂存区和 3 个 MOV
输入输出指令
其实也是传送指令,只是有一方固定为 IO 设备。可以用 MOV 取代 IO 指令。
I/O指令在设置上是比较灵活的一类。因为外围设备种类数量汇编,而且具体控制命令差别很大。
外围设备编址:
①对外围设备单独编址:
-
1)单独编址到设备级。在I/O指令中给出设备码,并指明是哪个寄存器。
-
2)单独编址到寄存器级 为各I/O接口中的有关寄存器分配一种I/O端口地址,即编址到寄存器一级。只要送出某个端口地址,就能知道选中了哪一个接口中的哪一个寄存器,也就知道选中了哪台设备。
直接寻址是 8 位,间接寻址是 16 位。数据量取决于使用的 CPU 寄存器
②外围设备与主存储器统一编址:
这一步同样编址到寄存器级。将每个外围设备接口中的有关寄存器视作一个主存单元,分配一个存储单元地址(总线地址)(所以会占用一部分内存的地址)
I/O指令的设置方法:设置专用的 IO 指令(IN OUT)/MOV/通过 IO 处理器控制(对命令字/状态字的设置问题: 命令字:启动位、校验位、维护位、允许中断位等。 状态位:忙位、完成位、空闲位、故障位、效验出错位等。)
Chapter 3 - 1 模型机的总体设计
指令格式
1、双操作数指令:这种指令格式同时包含源地址和目的地址。
| 位 (Bits) | 15 - 12 (4位) | 11 - 9 (3位) | 8 - 6 (3位) | 5 - 3 (3位) | 2 - 0 (3位) |
|---|---|---|---|---|---|
| 字段 | 操作码 | 寄存器号 | 寻址方式 | 寄存器号 | 寻址方式 |
| 说明 | 目的地址 | 源地址 |
2、单操作数指令:这种指令格式只有一个目的地址。
| 位 (Bits) | 15 - 12 (4位) | 11 - 6 (6位) | 5 - 3 (3位) | 2 - 0 (3位) |
|---|---|---|---|---|
| 字段 | 操作码 | (未使用 / 扩充) | 寄存器号 | 寻址方式 |
| 说明 | 目的地址 |
3、转移指令:这种指令格式包含转移地址和转移条件。
| 位 (Bits) | 15 - 12 (4位) | 11 - 9 (3位) | 8 - 6 (3位) | 5 - 4 (2位) | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| 字段 | 操作码 | 寄存器号 | 寻址方式 | (未使用) | N' | Z' | V' | C' |
| 说明 | 转移地址 | 转移条件(后同) |
寻址方式
| 序号 | 寻址方式 | 助记符 | 可指定寄存器 |
|---|---|---|---|
| 1 | 立即寻址 | I | 无 |
| 2 | 寄存器寻址(直接) | R | R₀~R₃, SP, PC, PSW |
| 3 | 寄存器间址 | (R) | R₀~R₃ |
| 4 | 自减型寄存器间址 | -(R) | R₀~R₃, SP (无PC) |
| 5 | 自增型寄存器间址 | (R)+ | R₀~R₃, SP, PC |
| 6 | 自增型双间址 | @(R)+ @(PC)+ | R₀~R₃, PC |
| 7 | 变址方式 | X(R) X(PC) | R₀~R₃, PC |
| 8 | 跳转方式 | SKP |
| 寻址方式 | 操作数地址1 (间址地址、形式地址的地址) | 操作数地址2 | 操作数位置 | 操作数的 访存次数 |
|---|---|---|---|---|
| 立即寻址: I | 指令中, 实 际在IR中 | 0 | ||
| 寄存器直接寻址: R | 指令给出R编号 (即操作数地址) | R中 | 0 | |
| R寄存器间接寻址: (R) | 指令给出R编号 (间接地址) | R中给出M单元号 (即操作数地址) | M中 | 1 |
| 自增型寄存器间接寻址: (R)+、(SP)+、(PC)+ | 指令给出R编号 (间接地址) | R中给出M单元号 (即操作数地址) | M中 | 1 |
| 自减型寄存器间接寻址: -(R)、-(SP) | 指令给出R编号 | R中内容减1后, 为M单元号 (即操 作数地址) | M中 | 1 |
| 自增型双间址: @(R)+ | 指令给出R编号 (间接地址) | 从M中取回的操作数地址 (即操作 数地址) | M中 | 2 |
| 变址寻址: X(R) | 指令给出M单元号 (形式地址的地址) | 指令给出R编号 (即变址地址N), 及从M中取回的形式地址D; 运算 后的M单元值A=D+N (即操作数地址) | M中 | 2 |
| 跳转: SKP |
操作类型
操作码共4位,设置15种指令(14种编码方式),余下两种操作码组合可供扩充: 1、传送指令:一种 2、双操作数算逻指令:五种 3、单操作数算逻指令:六种 4、程序控制类指令:三种,但其中两种操作码相同
0000 MOV ;0010 SUB; 0101 EOR
CPU 构成
-
运算器:三级,输入选择器 / 锁存器—>ALU—>移位器
输入选择器 / 锁存器:选择输入。数据来源有:(R0∽R3、C、D)ALU 的 AB 端都能送、(PC、SP)只送 A 端、(PSW、MDR)只送 B 端。
ALU:进行运算。由微命令M,S0,S1,S2,S3,C0选择操作功能。
移位器:作直接传送、左移、右移;由微命令实现直接、左、右移。
-
寄存器组:三组,用于处理、控制、作用于主存接口的寄存器
都是 16 位,内部是 16 个 集成 D 控制器。代码输入至D端,CP端同步打入,还可选由R、S端异步置入 (这种方式速度更快)。
编号:R0=000,R1=001,R2=010,R3=011,SP=100,PSW=101,PC=111
用于处理的寄存器:通用寄存器(可编程访问,有给编号)、暂存器(C 读取源操作数、D读取目的操作数或中间结果)。
用于控制的寄存器:IR 存放现行运行指令 ,输出是产生微操作命令序列的主要逻辑依据(有扩充成为指令队列、拉 DB 数据总线连主存来提速访问)、PC 提供后续指令地址送往 MAR 、PSW 表现现行程序的运行状态,如特征位:进位C、溢出V、零Z、负N,允许中断I等和编程设定位。
用于主存接口的寄存器:
MAR,CPU -> MAR -> 地址总线(微命令EMAR高电平发送,低电平断开)
补充:场效应管&三态门

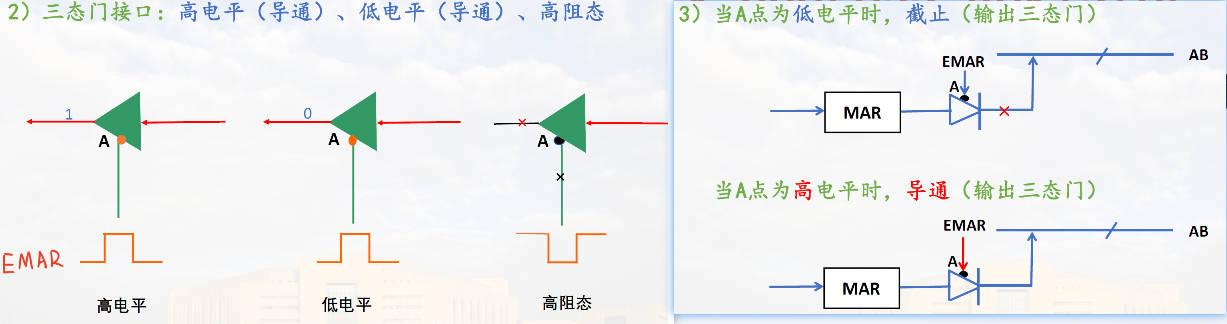
MDR:存数据。特殊情况(自增双间址)可以存地址。CB 控制总线中 RW 总线控制。高电平 R 低电平 W。R:由主存单元->数据总线->MDR;W:由MDR->数据总线->主存单元
-
总线:四组,CPU内总线、系统总线、部件间总线,外总线
是一组能为多个部件分时共享的公共信息传送线路,及相应的控制逻辑。分为 CPU 内总线(模型机中单向单组)、部件间总线(地址线 + 数据线)、系统总线(是计算机系统内各大部件进行信息交换的基础。地址总线 AB、数据总线DB、控制总线CB)、外部总线。
-
控制器:组合逻辑控制器/微程序控制器
-
时序系统:一个脉冲源、一组计数分频逻辑
周期、节拍、脉冲等信号称为时序信号,产生时序信号的部件称为时序发生器或时序系统,它由一个振荡器和一组计数分频器组成。
内部数据通路结构
取指令
PC -> MAR
M -> IR, PC -> PC + 1
每一行一个时钟周期

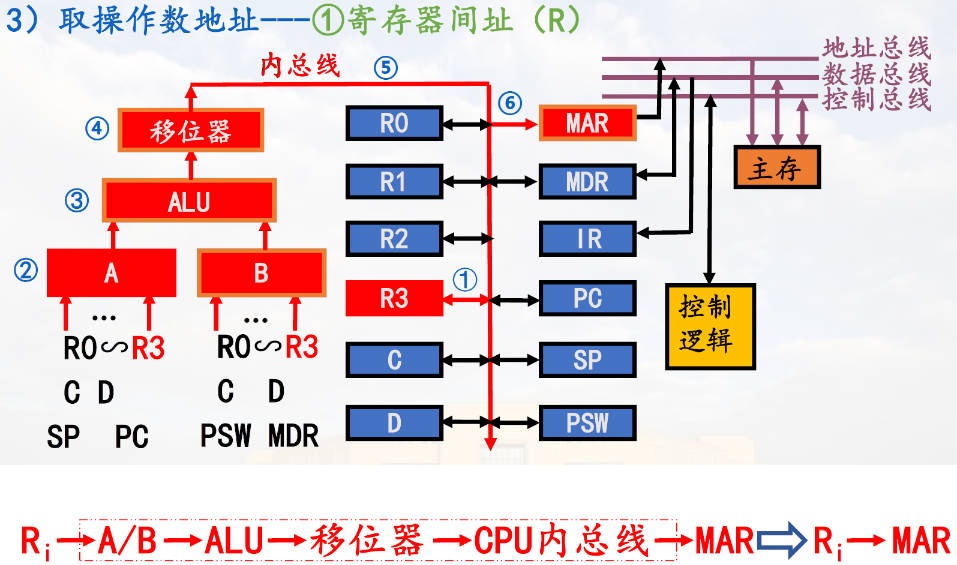
取操作数地址
寄存器间址
自减型寄存器间址
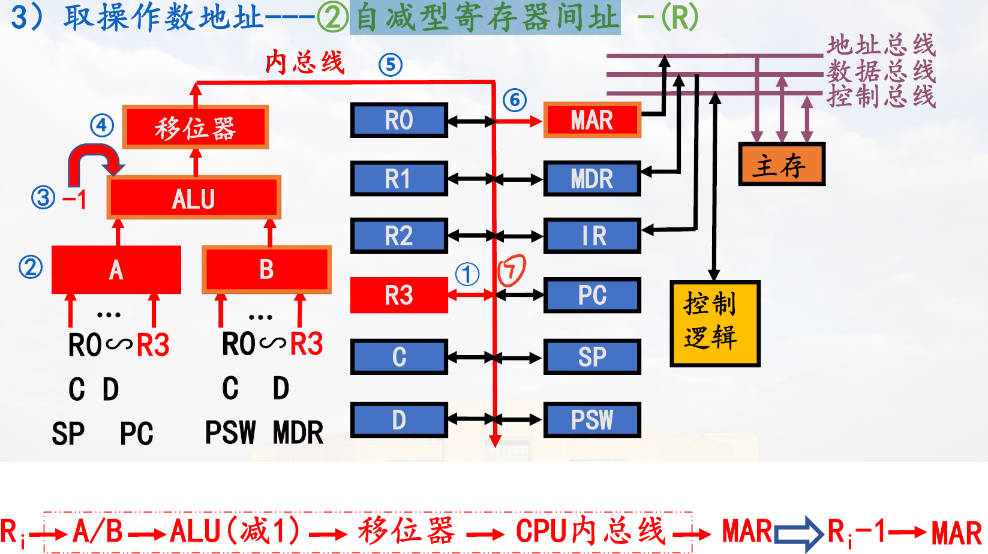 先减再用
先减再用
自增型寄存器间址
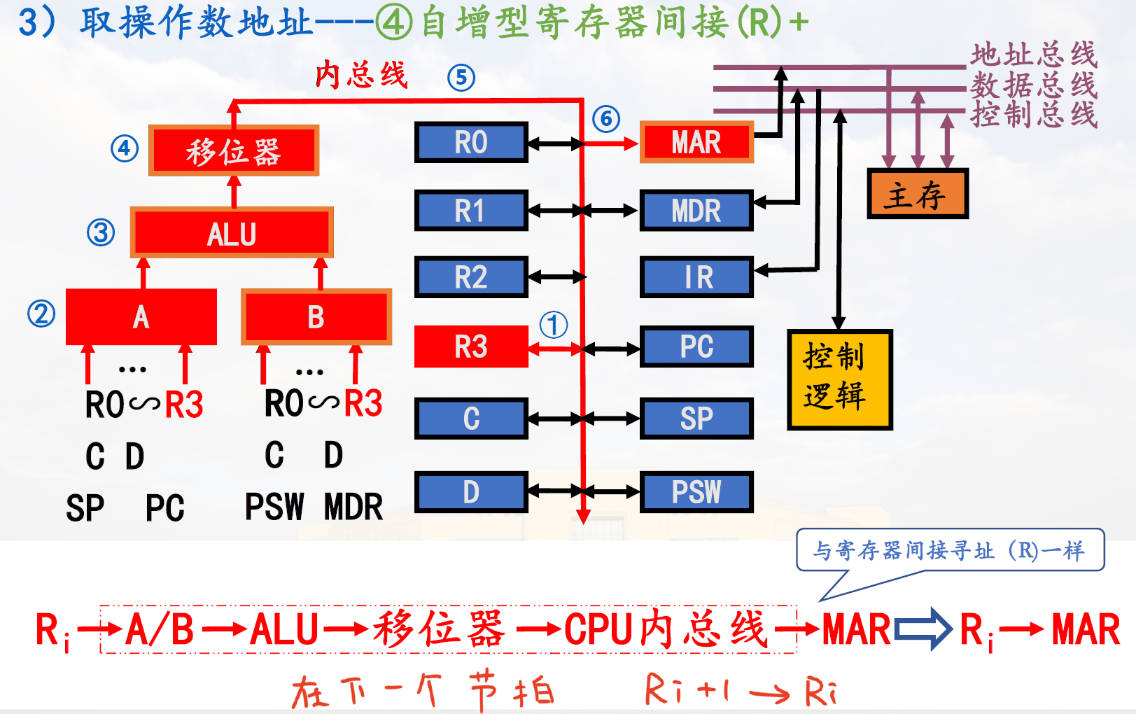 先用再加
先用再加
自增双间址
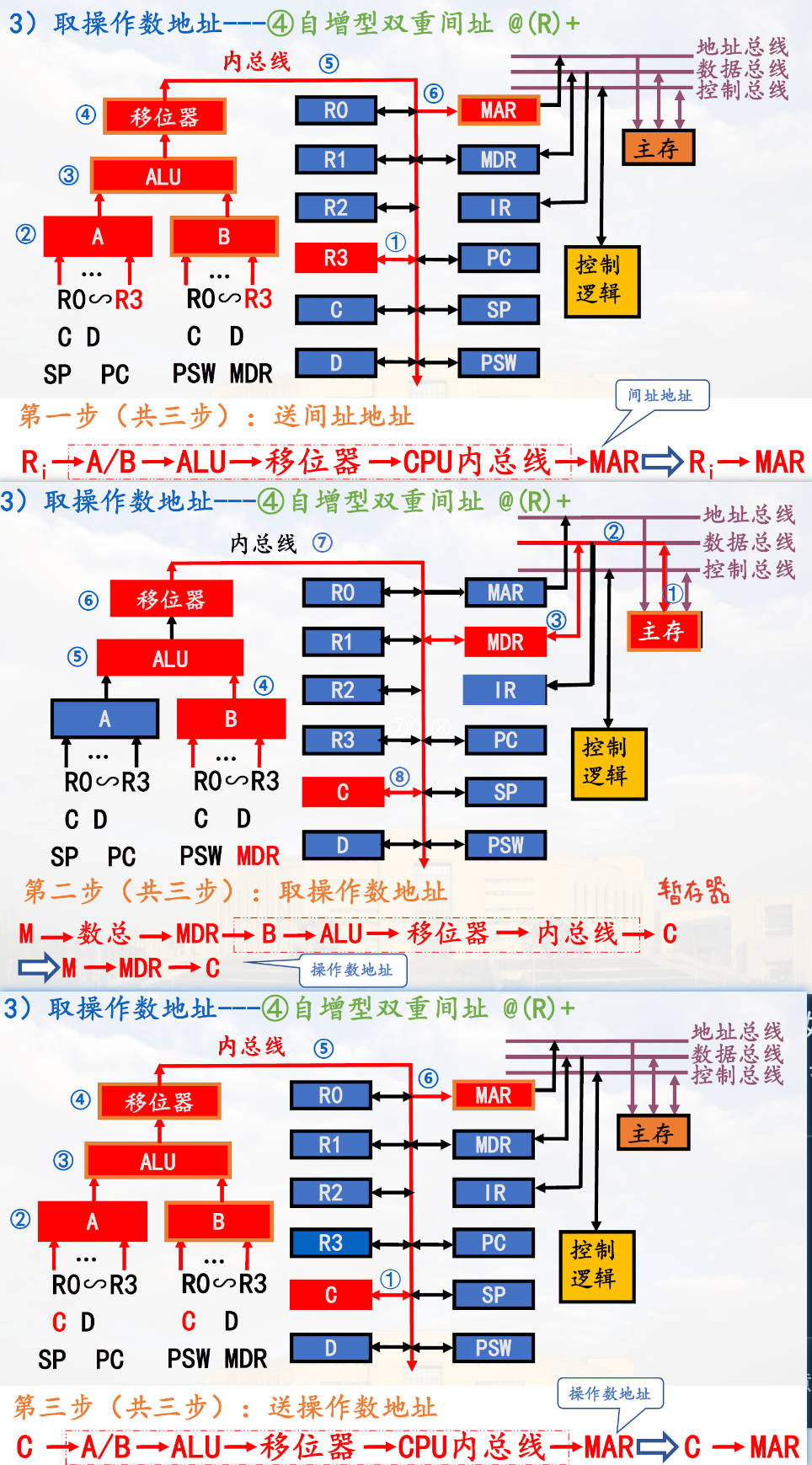
变址寻址

数据传送
共六种方式:R -> R、R -> M、M -> R、M -> M、R -> IO 、IO -> R
![]()
微命令设置(重要)
集成D触发器工作原理:1)同步打入(由D端打入。2)由R/S端异步置入
-
CPU 内部操作:
- ALU 输入选择。对 ALU 的 AB 端进行开放选择。($R_i \to A$ 等)
- ALU功能选择:S0~S3 控制运算,C0 分加减,M 代表类型。直接写算数表达式
- 移位器功能选择:直传 DM、左移 SL、右移 SR
- 分配脉冲:在CPU执行指令的过程中,由控制单元在特定时刻 发出的、用于选通(激活)某个特定寄存器(如 MAR、PC)的“写入”操作的定时控制信号,写为 CP + 寄存器名字
-
与系统线和主存有关的微命令:EMAR , R , $\bar W$ , SIR , SMDR
-
读入操作 ( 取指令 =
EMAR,R,SIR,读数据 =EMAR,R,SMDR)-
EMAR(Enable MAR):- 作用: 打开 MAR 到地址总线 (AB) 的三态门。
- 数据流:
MAR$\to$AB - 目的: 将要访问的内存地址发送给主存。
-
R(Read):-
作用: 在控制总线 (CB) 上发出“读”信号 (例如
R/W置为 1)。 -
目的: 通知主存执行“读”操作。
情况 A:读入的是“指令”
- 微命令:
SIR(Store to Instruction Register)(R/S端异步置入) - 数据流: 主存 $\to$
DB$\to$MDR$\to$内总线$\to$IR - 何时使用: 在“取指周期”使用。
情况 B:读入的是“操作数”
- 微命令:
SMDR(Store to Memory Data Register) - 数据流: 主存 $\to$
DB$\to$MDR - 何时使用: 在“执行周期”读取操作数时。数据停留在
MDR中,等待被ALU作为操作数B端($R_j \to B$)取用。
-
-
-
-
写入操作(EMAR, $\bar W$)
-
前提:要写入的地址已经送入
MAR。要写入的数据已经送入MDR。 -
EMAR(Enable MAR):- 作用: 同读操作,将
MAR中的地址发送到地址总线AB。 - 数据流:
MAR$\to$AB
$\bar W$ (Write):
- 作用:
- 在控制总线 (CB) 上发出“写”信号 (例如
R/W置为 0)。 - (隐含操作)打开
MDR到数据总线 (DB) 的三态门。
- 在控制总线 (CB) 上发出“写”信号 (例如
- 数据流:
MDR$\to$DB
- 作用: 同读操作,将
-
数据传送方式 & 数据通路
主机与外设的连接模式
辐射型/星型、总线型、通道型( I/O处理机)

对信息传送的控制方式
**直接程序传送方式 **: CPU直接利用I/O指令程序实现I/O传送,在外设工作期间, CPU不执行与I/O无关的操作
程序中断方式:CPU暂停执行现行程序,转去执行中断程序,以处理某些随机事态,并在处理完毕后自动恢复原程序的执行。实质是程序的切换过程。有随机性。
一个例子:CPU 执行一个程序(称为“程序A”),需要打印数据。CPU 向打印机控制器发出“打印”命令,并将数据交给它。 发出命令后,CPU 不等待。它立即“挂起”程序A,转而去执行一个完全不相关的“程序B”(例如,一个计算任务或响应用户界面)。I/O 设备并行工作:打印机开始缓慢地打印数据。与此同时,CPU 正在全速执行“程序B”。此时,CPU 和外设实现了并行工作。打印机完成了打印任务(或者它的缓冲区空了,需要新数据)。它会通过控制总线向 CPU 发送一个**“中断请求信号 (INTR)”。这就是外设“向CPU提出新请求”的方式。CPU 在执行每条指令的末尾,都会检查一下是否有中断请求。当它检测到打印机的中断请求时,它会立即停止当前正在执行的“程序B”。为了能稍后“无缝”地切换回“程序B”,CPU 必须记住它被打断时的所有状态。它会将当前程序计数器 (PC)、程序状态字 (PSW) 以及相关寄存器的内容压入堆栈 (Stack)。这个过程称为“保护现场”。然后执行中断服务程序 (ISR):CPU 通过中断信号识别出是“打印机”在请求服务。它会跳转到一个固定的内存地址**,那里存放着专门为打印机服务的程序,称为**“中断服务程序” (Interrupt Service Routine, ISR)。CPU 开始执行这个 ISR。ISR 的任务可能是:检查打印机状态、向打印机发送下一批数据等。ISR 执行完毕后,CPU 执行一条“中断返回 (IRET)”指令。该指令会将之前压入堆栈的 PC、PSW 等值弹回**到寄存器中。这个过程称为“恢复现场”。PC 和 PSW 恢复后,CPU 就回到了“程序B”被“打断”的那一条指令,继续执行,仿佛什么都没有发生过一样。
直接有储器访问方式(DMA)
直接依靠硬件在主存与I/O设备进行简单批量数据传送的一种工作方式,在传送期间不需CPU的程序干预。
(据说后面专门学,先(挖坑)
时序控制方式与时序系统
时序控制方式
同步控制:各项操作与统一的时序信号同。特点是周期长度固定,每个时钟周期完成一步操作。
异步控制方式:各项操作按其需要选择不同的时间。各操作之间的衔接与各部件之间的信息交换采取应答方式。没有统一的节拍划分与同步定时脉 冲,但存在着申请、响应、询问、回答一类的应答关系。
主从设备:申请使用总线,并获得批准后掌管总线控制权(平时在 CPU 手上)的设备,称为主设备,否则为从设备。特例:用 DMA 传输时,硬件为主设备。
指令序列间的衔接方式
时序系统
产生节拍,脉冲等时序信号的部件,称为时序系统。由振荡器和分数分频逻辑(对周期乘除)组成
时序划分的层次:
指令周期:读取并执行一条指令所需的时间,称为指令周期。一般不作为时序的一级。
(CPU)工作周期:在指令周期中的某一工作阶段所需的时间,称为一个工作周期。一般不同。
时钟周期(节拍):是时序系统中最基本的时间分段。各节拍的长度相同。
定时脉冲(工作脉冲):有的操作如打入R,还需严格的定时脉冲,以确定在哪一刻打入。
多级时序
二级时序:一个指令周期由多个节拍组成。
三级时序:一个指令周期由多个工作周期组成,每个工作周期由多个时钟周期组成。
Chapter 3 - 2
加法单元
在这里 上文有讲
串行加法器
其实就是每次只求一位和,速度特别慢

并行加法器
由 n 位加法器和进位链组成。根据输入量(指Ci-1)提供时间的不同,将进位链分为带串行进位链的并行加法器,带并行进位链的并行加法器。加法器的运算速度不仅与全加器的运算速度有关,更主要的因素是取决于进位传递速度。
串行进位链直接依赖于低一级的信号($Cn = Gn + PnCn-1$),而并行则直接推到到底($Cn = Gn + PnGn-1 + …+ Pn…P1C0$)。

还有灵活分组的:组内并行,组间并行(实际为串行)的进位链
ALU 单元
一位的:由 1 位加法器,1 位输入控制器(逻辑运算),1 个公共控制门(算数还是逻辑运算)组成
四位:(挖坑)
Chapter 3 - 3 运算方法
定点加减法
全部基于补码。
$(X+Y){\text{补}}=X{\text{补}}+Y_{\text{补}}$
当操作码为“加”时,可直接将两个补码表示的操作数 ($X_{\text{补}}, Y_{\text{补}}$) 相加 7,不必考虑它们的符号,所得结果即为补码表示的和 8。
$(X-Y){\text{补}}=X{\text{补}}+(-Y)_{\text{补}}$ 9
当操作码为“减”时,可转换为与减数的负数相加 ,从而化“减”为“加” 。
由 $Y_{\text{补}}$ 求 $(-Y){\text{补}}$ 称为“求补”或“变补” 1313:即将 $Y{\text{补}}$ 连同符号位一起按位取反,并在末位加1
因此有规则:
- 参与运算的操作数均用补码表示 。
- 符号位作为数的一部分直接参与运算 ,运算结果也为补码形式 。
- 若操作码为“加”,则两数直接相加 。
- 若操作码为“减”,则将减数“变补”(连同符号位取反,末位加1)后再与被减数相加 。
所需命令:+A、+B(或 + $\bar B$)、A+B(或 $A + \bar B + 1$)、$\sum \to A$、 CPA
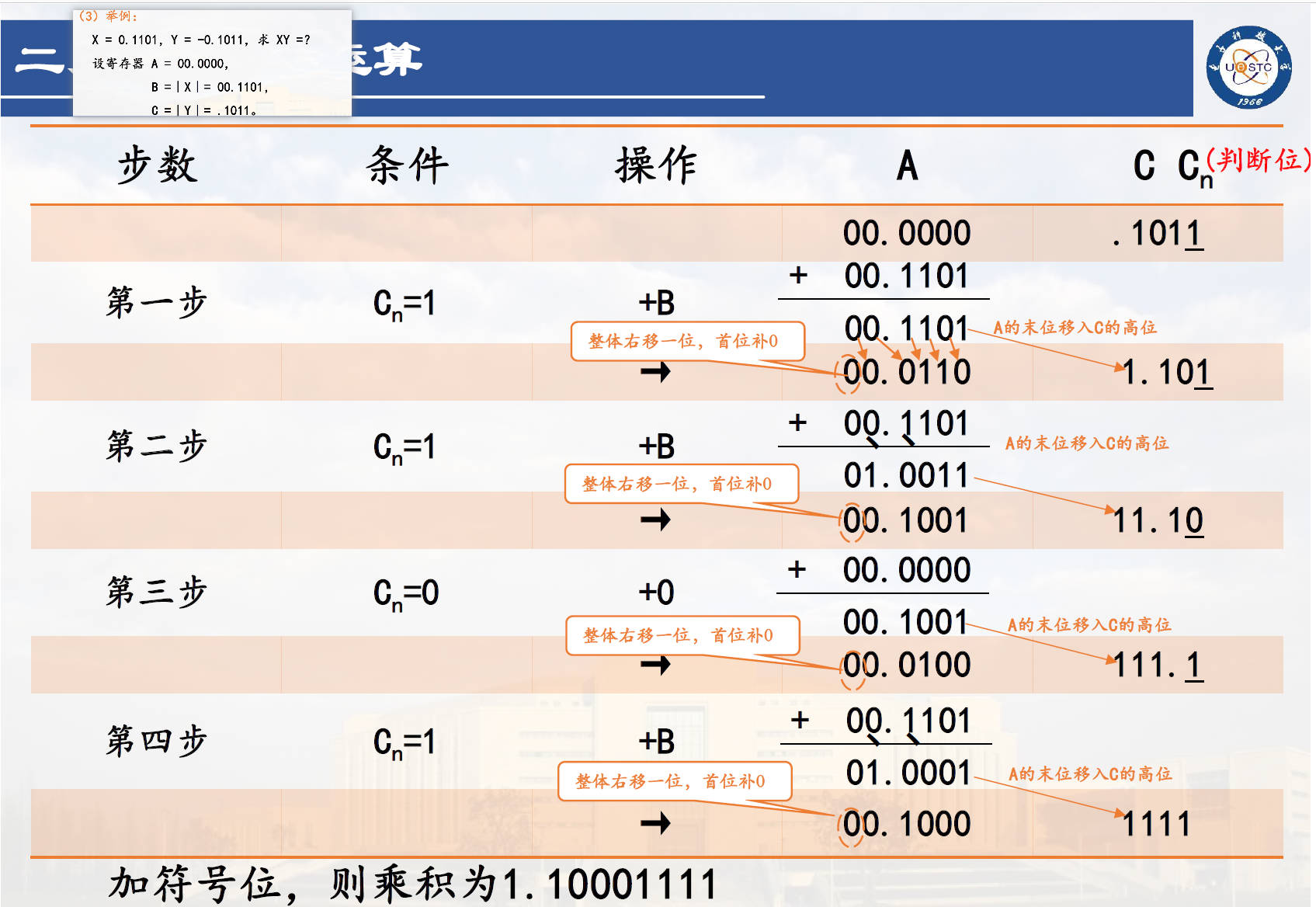
原码一位乘法
(此处讨论常规加法器,通过累加、移位实现分步乘法)
取两个操作数的绝对值相乘,每步处理一位乘法,符号位单独处理。
运算规则
①寄存器分配与初始值:A存放部分积累加和,初始值为0(双符号位00表示);B存放被乘数X(绝对值),此时,符号位为双符号位00;C存放乘数Y(绝对值),将符号位去掉;C寄存器的初始值是乘数Y的尾数(有效位数),以后每乘一次,将已处理的低位乘数右移舍去,同时将A寄存器的末位移入C寄存器的高位。
②符号位:A,B均设置双符号位(方便地检查溢出)
③基本操作
在原码一位乘中,每步只处理一位乘数,即位于 C 寄存器末位的乘数,也称之为判断位 Cn;
若Cn=1,则部分积为B,执行A+B操作,然后将累加和右移一位,用“→”表示。(Cn位去掉);执行部分积累加和+B操作,然后将新部分积累加和右移一位;
若Cn=0,则部分积为0,执行A+0操作,然后右移,或直接让A右移一位。(Cn位去掉)
右移时,A的末位移入C的高位,A的第二符号位移入尾数最高位,第一符号位移入第二符号位,而第一符号位本身则补0。
④操作步骤:n 次累加与 n 次移位(最后一次累加后要移位)
⑤处理符号位
一个例子:
一些疑惑点
为什么可以通过不断右移+累加计算?
二进制乘法,0 就是加 0 次,1 就是加 1 次。位置移动可以与正常乘法同理。通过不断对 A 移动,保证每次累加的位置都是正确的。
为什么 C 寄存器可以存放乘积低位?
- 在 $n$ 步循环中,C 寄存器中的原始乘数位从右边($C_n$)一位一位地被“消耗”掉(用于判断后舍弃)10。
- 同时,A 寄存器中的部分积由于不断累加和右移,其最低位($A_n$)会从 A 的右边溢出。
- 算法巧妙地将 A 溢出的 $A_n$“塞”入 C 寄存器左边($C_1$)空出的位置 11。
- $n$ 步之后,C 的 $n$ 位原始乘数已全部舍弃,并被 $n$ 位来自 A 的“部分积低位”填满,C 寄存器就自动“转型”为乘积的低位寄存器。
为什么 A 和 B 需要双符号位?
- 这是为了防止中间累加步骤的“假溢出”导致数据丢失。
- 因为我们处理的是绝对值, $A$ 和 $B$ 都是正数。当两个正数 $A$ 和 $B$ 相加时,结果可能暂时超过 1.0,例如:
00.1000 + 00.1100 = 01.0100。 - 如果使用单符号位,结果会是
1.0100,变成负数,数据出错。 - 使用双符号位
01.0100,这个1被安全地保存在第二符号位上。在紧接着的“右移”步骤中,这个1会被移入尾数最高位(00.1010),数据得以完整保留,运算继续。
硬件逻辑框图:
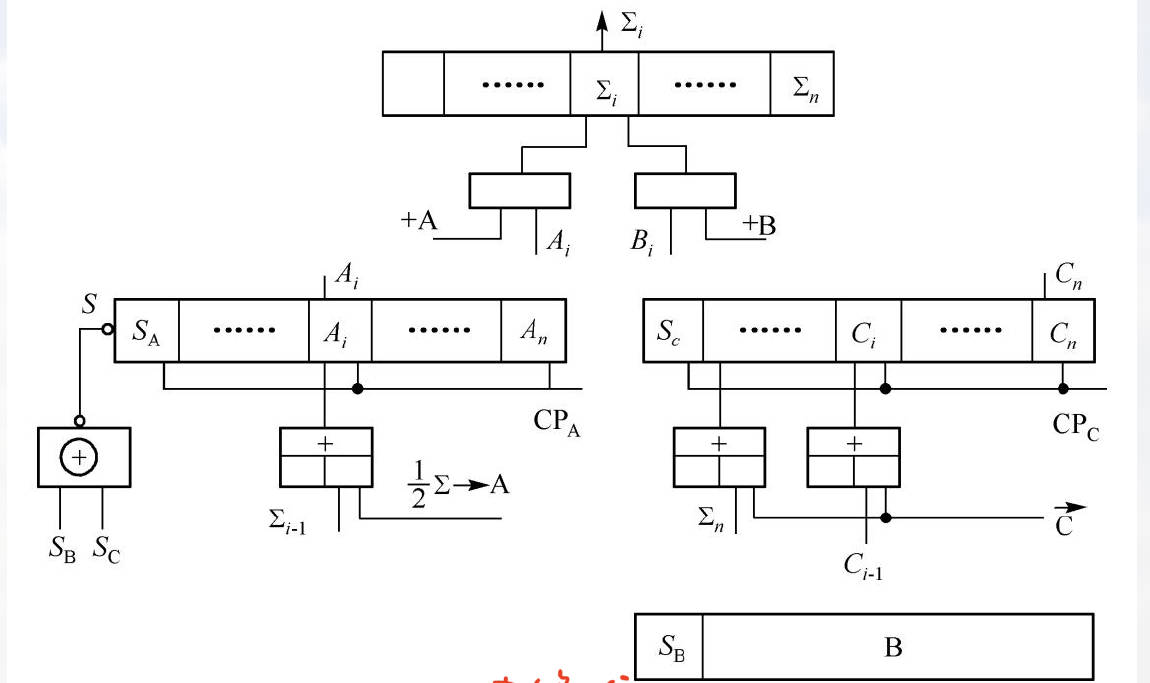
所需微命令:
注意,$ \sum / 2$由右移一位实现。$\vec C$ 为右移一位
Cn = 1,即 A+B:(+A、+B); A+B;(Σ/2→A、$\vec C$,CPA、CPC)
Cn = 0,即 A+0:(+A);A;(Σ/2→A、$\vec C$ 、CPA、CPC)
原码不恢复余数除法
同样讨论常规除法器
取两个操作数的绝对值相除,符号位单独处理,根据余数 ri 符号判断是否够减。
此方法要求被除数 X 和除数 Y 满足 $|X| < |Y|$,且此为定点小数设计。
初始化:$r_0 = X - Y$
循环执行 n 次:
ri 为正表示够减,上商Qi = 1,下一步执行 2$r_i - Y$ ri 为负表示不够减,上商Qi = 0;下一步执行 $2r_i + Y$
Qi 按照顺序在存答案的寄存器中从后向前进入 0000 -> 0001 -> 0010 –> 0101这样子。
在执行完 n 次之后,若 r < 0,则 r + Y 为最后的余数。
为什么可以通过加减 Y 来避免出现减不够?
不妨以相邻两步看:第一步 $2r_i - Y$,第二步 $2r_{i+1} + Y$,代入有 $2 \times (2 r_i - Y) + Y \to 4 \times r_i - Y$,等价于两步只减了一次。如果还不够减,同理可得,三步内只减了一次。
所需微命令:
$r_i = 0$,即 $Q_i = 1$,则 $2r_i - Y$:
- $+\overleftarrow{A}$、 $+\overline{B}$;
- ${2A \rightarrow \Sigma}$、 $+\overline{B}$、 $+1$;
- ${\Sigma \rightarrow A}$、 ${\overleftarrow{C}}$、 $ {Q_i \rightarrow C_n}$、 ${CP_A}$、 ${CP_C}$
$r_i = 1$,即 $Q_i = 0$,则 $2r_i + Y$:
- $+\overleftarrow{A}$、 $+B$;
- ${2A \rightarrow \Sigma}$、 $+B$;
- ${\Sigma \rightarrow A}$、 ${\overleftarrow{C}}$、 ${Q_i \rightarrow C_n}$、 ${CP_A}$、 ${CP_C}$
最后一步中,若余数为负,则需要恢复余数操作。
Chapter 3 - 4 组合逻辑控制器
定义:组合逻辑控制器的微命令(控制信息)是由组合逻辑电路(& | !)来实现。每种微命令都需要一组逻辑电路产生。
概述(回头再看。)
工作原理:从主存读取的现行指令存放在IR中,其中,操作码与寻址方式代码分别经译码电路形成一些中间逻辑信号,送入微命令发生器,作为产生微命令的基本逻辑依据。
微命令的形成还需考虑各种状态信息,如PSW所反映的CPU内部运行状态、由控制台(如键盘)产生的操作员控制命令、I/O设备与接口的有关状态、外部请求等等。
微命令是分时产生的,所以还需引入时序系统提供的周期、节拍、脉冲等时序信号。 IR中的地址段信息送往地址形成部件,按照寻址方式码形成实际地址,或送主存以访问主存单元;或送往运算器,按指定的寄存器号选取相应的寄存器。 当程序顺序执行时,PC增量计数,形成后续指令的地址; 当程序需要转移时,IR中的地址段信息经地址形成部件产生转移地址,送入PC,使程序发生转移。
时序系统
工作周期
一共有六个工作周期。用六个周期状态触发器(6 个 D 触发器)来标志。其中四个用于指令的正常执行,还有两个用于 IO 传送控制。在任意一个时态,只有一个触发器为 1。
指令正常执行的周期:
取指周期(FT): M -> IR 所有指令都有
源周期(ST):如果需要从主存中读取源操作数,则进入。
目的周期(DT):如果需要从主存中读取目的地址或者目的操作数,则进入。
只有 (R)、-(R),(R)+,@(R)+,X(R)才有 ST 和 DT。
执行周期(ET):取得操作数之后,进入 ET。所有指令都有
用于 IO 传送的周期:
中断周期(IT):在响应中断请求之后,到执行中断服务程序之前,需要一个过渡期(执行断点保护),称为中断周期IT。
DMA 周期(DMAT):响应DMA请求之后,CPU进入DMAT。在DMAT中,CPU交出系统总线的控制权,即MAR、MDR与系统总线断开(呈高阻态),改由DMA控制器控制系统总线,实现主存与外围设备间的数据直传。
流程图如下(注:双操作数,单操作数都是指需要从主存中读取的操作数,下同)
graph LR
A[FT] -- "双操作数" --> C[ST];
A[FT] -- "单操作数" --> D[DT];
C --> D;
D --> E[ET];
E -- "如果出现外设的故障,那么先跳转到中断(优先级最高)" --> H
E -- "有 DMA 请求" --> G["DMAT (可循环)"];
E -- "无 DMA 请求" --> H{中断请求 ?};
G --> H;
H -- "Y" --> I[IT];
H -- "N" --> A;
I --> J(进入中断程序);
时钟周期(节拍)
指令的读取与执行有CPU内部数据通路操作,也有访问主存的操作。
模型机将两类操作周期统一起来,即以主存访问周期所需时间为时钟周期的宽度,这里设为1微秒。
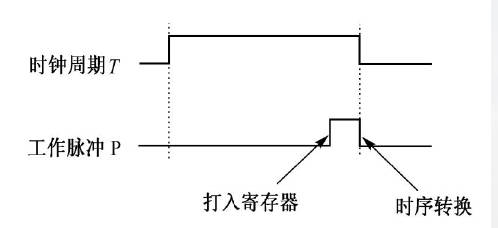
工作脉冲
有些操作需要同步定时脉冲进行控制,如将稳定的运算结果打入寄存器,又如进行周期状态切换。
因此引入一个同步信息:工作脉冲。模型机在每个时钟周期的末尾发一个工作脉冲 P,作为各种同步脉冲的来源。工作脉冲有前沿和后沿。
前沿作为打入寄存器的定时,标志着一次数据通路操作的完成。通常就是 CPX 的信号本身。
后沿作为时序转换的定时。在这个时候,如果工作周期没有结束,则对时钟周期计数器 T 计数,进入新的节拍。若结束,则将 T 清零,清除本工作周期的状态标志,设置新的工作周期状态标志。
指令流程和操作时间表
指令流程: 在寄存器传送级拟定各类指令的执行流程,也就是确定指令执行的具体步骤,即各类信息如何分步地按要求流动。
操作时间表:即给出实现上述流程所需的微操作命令序列。其中包含维持一个时钟周期的电位型微命令,以及短暂的脉冲型微命令。操作时间表还将表明出现各种微命令的逻辑条件与时间条件。
形如:
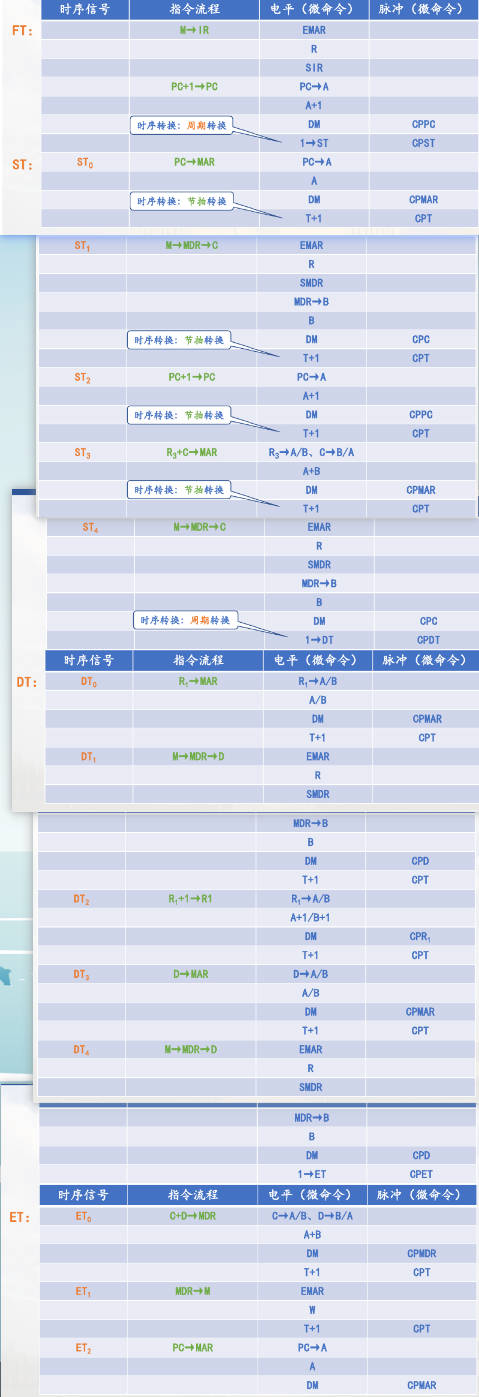
| 时序信号 | 指令流程 | 电平(微命令) | 脉冲(微命令) |
|---|---|---|---|
| $ST_0$ | Ri -> MAR | Ri →A/B | |
| A/B | |||
| DM | CPMAR | ||
| T + 1 | CPT |
下文不再列表(太占空间了)。但是按照格式写。
注:下面我们先讨论双操作数的指令,例如 ADD X Y。
取指周期(IT)
R/S 异步置入(当且仅当是上电初始化或者复位初始化的时候)或者运算过程中同步打入 FT(从 D 端)
流程:M -> IR, PC + 1 -> PC 同一个节拍内完成。
操作时间表:
M -> IR : EMAR, R, SIR;
PC + 1 -> PC : PC -> A, A + 1, DM, CPPC.
最后一步,要改变状态,根据下一步的情况选择:
双操作数:1 -> ST, CPST
单操作数:1 -> DT, CPDT
没有需要从主存中取出的操作数:1 -> ET, CPET
ST
MOV,双操作数指令会进来。需要分类。
(R):
$ST_0$ : Ri -> MAR : Ri -> A/B, A/B, DM, CPMAR, T + 1, CPT
$ST_1$ : M -> MDR -> C: EMAR, R, SMDR, MDR -> B, B, DM, CPC, 最后一步状态转移根据下一个操作决定(此处为了方便扩展 DT)。
-(R):
$ST_0$ : Ri - 1 -> Ri, MAR : Ri -> A/B, A/B - 1, DM, CPMAR, CPRi, T+1, CPT
$ST_1$ : M -> MDR -> C : EMAR, R, SMDR, MDR -> B, DM, CPC,最后一步同理要看下一步
(R) +:
$ST_0$ : Ri -> MAR : Ri -> A/B, A/B , DM, CPMAR, T + 1, CPT(这一整步吃 CPU 内总线)
$ST_1$: M -> MDR -> C : EMAR, R, SMDR, MDR -> B(ONLY!), B, DM, CPC, T + 1, CPT(吃 DB & CPU 内总线)
$ST_2$ : Ri + 1 -> Ri : Ri -> A/B, A/B + 1, DM, CPRi, 最后一步同理要看下一步(占 CPU 内总线)
二三步可以换序或者同时,但是模型机不能()
@(R)+:
$ST_0$ : Ri -> MAR : Ri -> A/B, A/B, DM, CPMAR, T + 1, CPT $ST_1$ : M -> MDR -> C : EMAR, R, SMDR, MDR -> B, B, DM, CPC; T + 1, CPT
$ST_2$ : Ri + 1 -> Ri : Ri -> A/B, A/B + 1, DM, CPRi, T + 1, CPC
$ST_3$ : C -> MAR : C -> A/B, A/B, DM, CPMAR, T + 1, CPT
$ST_4$ : M -> MDR -> C : EMAR, R, SMDR, MDR -> B, B, DM, CPC, 最后一步同理要看下一步
X (R):
$ST_0$ : PC -> MAR : PC -> A, A, DM, CPMAR, T + 1, CPT
$ST_1$ : M -> MDR -> C : EMAR, R, SMDR, MDR -> B, B, DM, CPC, T + 1, CPT
$ST_2$ : PC + 1 -> PC : PC -> A, A + 1, DM, CPPC, T + 1, CPT
$ST_3$ : Ri + C -> MAR: Ri -> A/B, C -> A/B, A + B, DM, CPMAR, T + 1, CPT
$ST_4$ : M -> MDR -> C : EMAR, R, SMDR, B, DM, CPC,
DT
和 ST 几乎一样。MOV, 双操作数指令。
区别:MOV 指令缺少取出操作数,因为是直接把当前位置覆盖过去。也就是:M -> MDR -> D
ET
在这个周期,CPU 将会执行任务。例如 MOV R0, R1 这里就会执行 R1 -> R0。然后在最后会为下一条指令做好准备,即 PC -> MAR。
总览
先定义一下分支。这个分支主要是为了便于想那个表里面怎么规划的。
| 类型 | 寻址方式及含义 |
|---|---|
| $SR$ | 源操作数采用 R寻址,表明源操作数在CPU内的寄存器中。 |
| $\over {SR}$ | 源操作数寻址采用 (R)、-(R)、(R)+、@(R)+、X(R) 中任意一种,表明源操作数在主存中。 |
| $DR$ | 目的操作数采用 R寻址,表明目的操作数在CPU内的寄存器中。 |
| $\over{DR}$ | 目的操作数寻址采用 (R)、-(R)、(R)+、@(R)+、X(R) 中任意一种,表明目的操作数在主存中。 |
那么所有的情况可以分为四种分支,分别给出对应的例子。DR 在主存,结果就需要保存到主存;在寄存器,那么结果就需要保存到寄存器。
$SR \cdot {DR} $
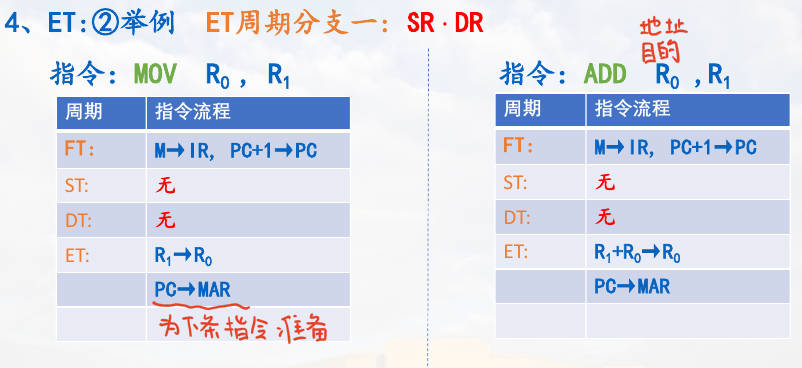
$SR \cdot \overline{DR} $
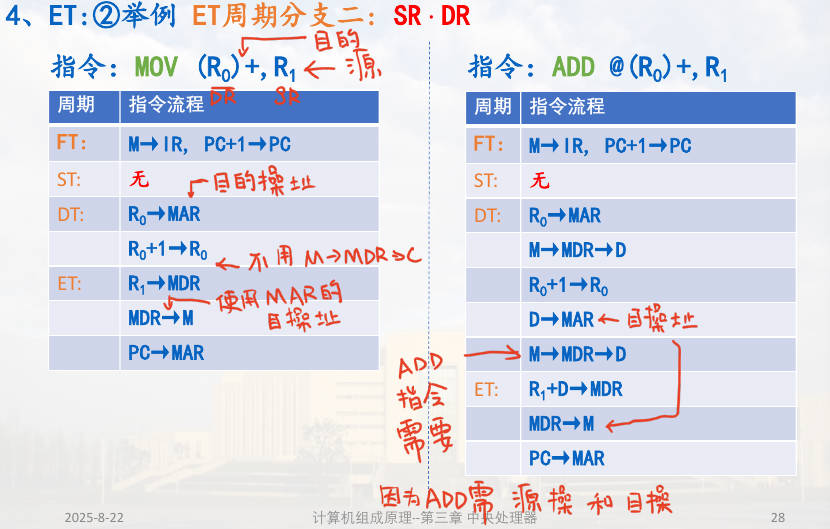
$ \overline{SR} \cdot{DR} $
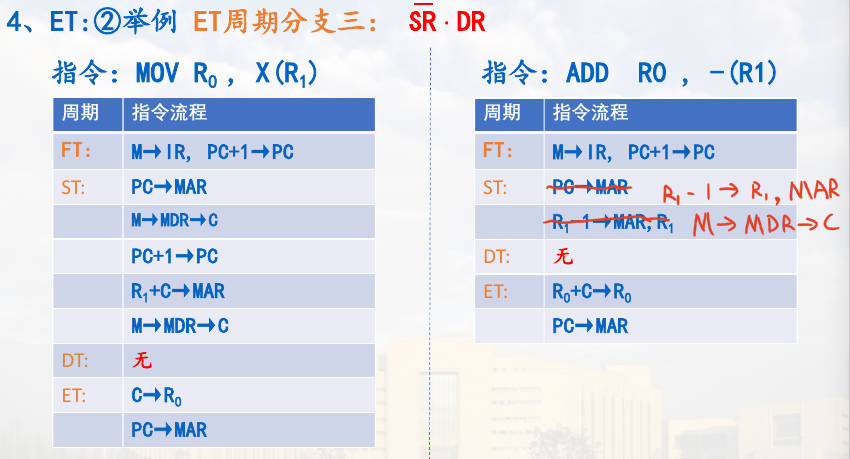
$ \overline{SR} \cdot \overline{DR} $

针对其中一个指令流程,给一个微命令的例子(
例如:$SR \cdot \overline{DR}$ :
$ET_0$ : Ri -> MDR : Ri -> A/B, A/B, DM, CPMDR, T + 1, CPT
$ET_1$ : MDR -> M : EMAR, W, T + 1, CPT
$ET_2$ : PC -> MAR : PC -> A, A, DM, CPMAR, 最后一步同理要看下一步(1->?, CP??)
很好的例题,使我的大脑旋转:拟定指令“ADD @(R1) +,X (R3)”的执行流程及操作时间表
对于单操作数指令:FT 周期一模一样,没有 ST 周期,DT 周期也一模一样,ET 周期就只有两种分支。即$DR$ 和 $\overline{DR}$。
$DR$ : OP Ri
$ET_0 : OP\space R_i \rightarrow R_i : R_i \rightarrow A/B, OP A/B, DM, CPR_i, T+1, CPT$ $ET_1 : PC \rightarrow MAR : PC \rightarrow A, A, DM, CPMAR$,最后一步根据下一步看:$(1) 1 \rightarrow FT?, CPFT?, (2) 1 \rightarrow DMAT?, CPDMAT?, (3) 1 \rightarrow IT?, CPIT?$
$\overline{DR}$ : OP D
$ET_0 : OP\space D \rightarrow MDR : D \rightarrow A/B, OP A/B, DM, CPMDR, T+1, CPT$ $ET_1 : MDR \rightarrow M : EMAR, W, T+1, CPT$ $ET_2 : PC \rightarrow MAR : PC \rightarrow A, A, DM, CPMAR, (1) 1 \rightarrow FT?, CPFT?, (2) 1 \rightarrow DMAT?, CPDMAT?, (3) 1 \rightarrow IT?, CPIT?$
对于转移指令 JMP 和返回指令 RST:(RST 指令是 JMP 指令的一种特例)
一样的 FT 周期,没有 ST、DT 周期。在 ET 周期中,转移成功 JP 或者转移不成功 NJP。这部分在转移指令流程讲(挖坑)
对于转子指令 JSR:分为转子不成功NJSR指令与转子成功JSR指令。
- 转子不成功NJSR指令:只有FT及ET周期
- 转子成功JSR指令:有FT周期、或ST周期(寻址方式决定)、ET周期
转子指令要能够返回跳走的位置,不同于转移指令。因此,在执行子程序前,本命令的 ET 周期进行断点保存和现场保护。
保存断点、现场保护的方式如下:
| 时序信号 | 指令流程 | 电平 (微命令) | 脉冲 (微命令) |
|---|---|---|---|
ET₀ |
SP-1→SP、MAR |
SP→A |
|
A-1 |
|||
DM |
CPSP、CPMAR |
||
T+1 |
CPT |
||
ET₁ |
PC→MDR |
PC→A |
|
A |
|||
DM |
CPMDR |
||
T+1 |
CPT |
||
ET₂ |
MDR→M |
EMAR |
|
W |
|||
T+1 |
CPT |
||
...... |
...... |
...... |
...... |
IT(挖坑)
断点保护/现场保护+获取入口地址(查表)
DMAT(挖坑)
关闭三态门,移交系统总线控制权给告诉外设
组合逻辑控制方式的优缺点
优点:产生微命令的速度快。
缺点:设计不规整,不易修改或扩展
Chapter 3 - 5 模型机的微程序控制器
基本概念与原理
微命令:构成控制信号序列的最小(或最基本)单位,又称微信号,指那些直接作用于部件或控制门电路的命令。
微操作:由微命令控制实现的最基本的操作称为微操作
微周期:从控制存储器中读取一条微指令并执行相应的一步操作所需的时间,称为一个微周期或微指令周期。通常一个时钟周期为一个微周期
微指令:每个微周期的操作所需的微命令组成一条微指令。
微程序:一系列微指令的有序集合称为微程序,用来解释执行一条机器指令
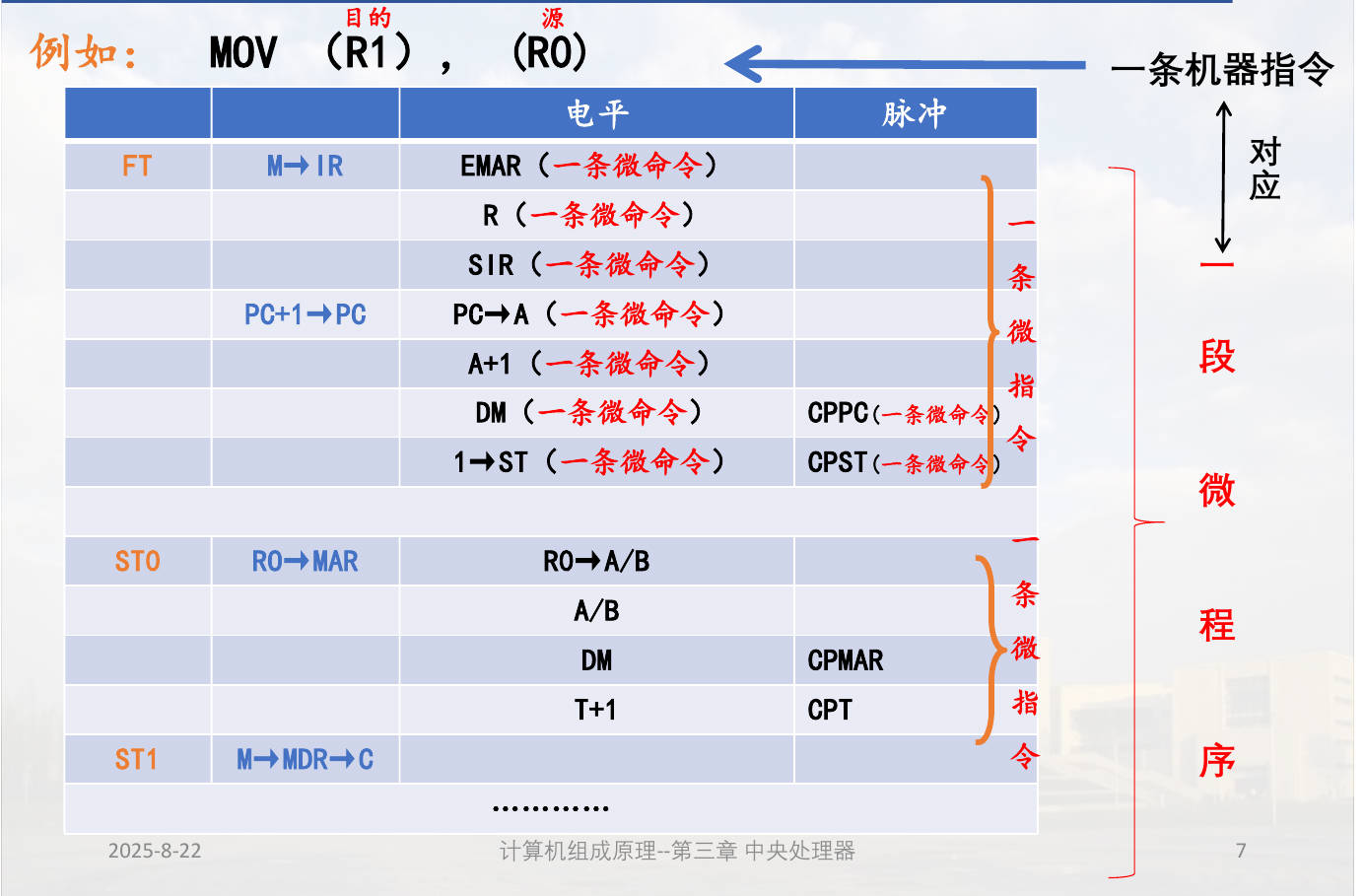
微程序控制 : 将控制器所需的微命令,以代码(微码)形式编成微指令,存入一个ROM构成的控制存储器中。(将存储逻辑引入 CPU)将各种机器指令的操作分解为若干微操作序列。(将程序技术引入 CPU 的构成级)
微程序控制器和组合逻辑控制器的区别:微命令产生方式不同,时序设计不同(微程序控制器是 2 级,组合逻辑控制器是 3 级)。
微程序控制器的硬件组成
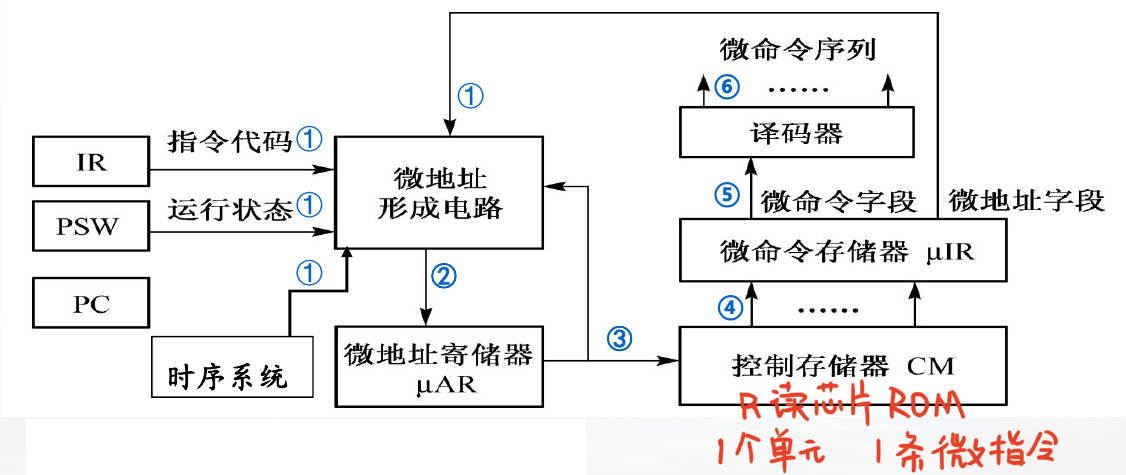
IR、PSW、PC、时序系统、控制存储器CM、微指令寄存器µIR、微地址形成电路、微地址寄存器µAR、译码器
控制存取器CM:用来存放微程序,它的每一单元用来存放一条微指令,一段微程序需要几十位。
微指令寄存器µIR:从 CM 读取的微指令,存放于 µIR 中。分为微操作控制段:产生微命令的依据(相当于I中的操作码)和顺序控制字段:产生后继微地址指令的依据,用以控制微程序的连续执行。
微地址形成电路:根据微程序执行顺序的需要,应有多种后继微指令地址的形成方式。依据以下几种信息的一部分去形成后继微地址:顺序控制字段,现行微指令地址,微程序转移时的微地址等
微地址寄存器µAR:在从CM中读取µI时,µAR中保存着CM的地址(微地址),指向CM单元(如同PC或堆栈指针)。读出微指令或完成一个微指令周期操作后,微地址形成电路将后继微地址打入µAR中,为读取下一条微指令做准备。
微程序工作原理
执行指令时,从控制存储器中找到相应的微程序段,逐次取出微指令,送入微指令寄存器,译码后产生所需微命令,控制各步操作的完成。