相关知识点
数字图像处理、 计算机图形学、模式识别三门课之间的关系
-
数字图像处理:利用计算机进行分析处理,继而再现图像。(图像 -> 图像,对一张已有的图片进行处理)
-
计算机图形学:研究图形的计算机生成和基本图形操作,从数据描述到图形生成的过程。(描述数据 -> 图像,无中生有)
-
模式识别:计算机对图形信息进行的识别和分析描述,是从图像到描述表达的过程。(图像 -> 描述数据)
(图形处理 & 图像处理)
| 图形处理 | 图像处理 | |
|---|---|---|
| 数据来源 | 多来源于主观世界,人为地由计算机产生,由数据描述而生成图形 | 多来源于客观世界,来自对实物的拍摄、拾取,由图形再到图形的生成 |
| 处理方法 | 图形处理技术包括:几何变换,拟合,图形操作,图形模型产生,图形处理,隐藏线,面的消除,浓淡处理,色彩纹理处理,图案生成等 | 图像处理技术包括:图像几何修正(校正),图像采集、存储、编码、滤波、增强、压缩、复原、重建、图形理解识别等 |
| 理论基础 | 多利用数学矩阵代数、计算几何、分形几何等 | 多利用二维数字信号滤波,各种信号正交变换等 |
| 应用领域 | 多应用CAD/CAM/CAE/CAI等领域,以及计算机艺术、计算机模拟、计算机动画、多媒体系统应用等 | 多应用于多媒体系统,医学,遥感遥测,工业控制,监测监视,天文气象,军事侦察等 |
图形管线的各个阶段工作
应用程序阶段 - 几何阶段(模型与视点变换 - 光照 - 投影 - 裁剪 - 屏幕映射) - 光栅阶段 - 片元处理 - 输出合并
-
应用程序阶段:进行碰撞检测、物理模拟、动画计算,视锥体剔除,准备数据并发送给 GPU
-
几何阶段
- – 以下是顶点着色器的工作 –
- 模型变换(将物体从自身的局部坐标系移动到世界坐标系,也就是摆放物体)
- 视图变换(世界坐标系转换到观察空间)
- 光照:顶点光照,计算顶点颜色 (固定管线的光照)
- 投影:生成裁剪空间坐标
- — 以上是 顶点着色器 的工作 —
- 裁剪:完全在外部的丢弃,跨越的切割生成新的顶点。
- 屏幕映射:映射到屏幕像素坐标
-
光栅化阶段
- 三角形设置 / 图元组装
- 三角形遍历,生成片元 & 插值
-
片元着色器:计算当前片元的最终颜色(采样纹理,计算光照,应用阴影)
-
输出合并 / 逐片元操作 (alpha 测试,深度测试,混合)
计算机图形处理架构(有GPU模式和无GPU模式)
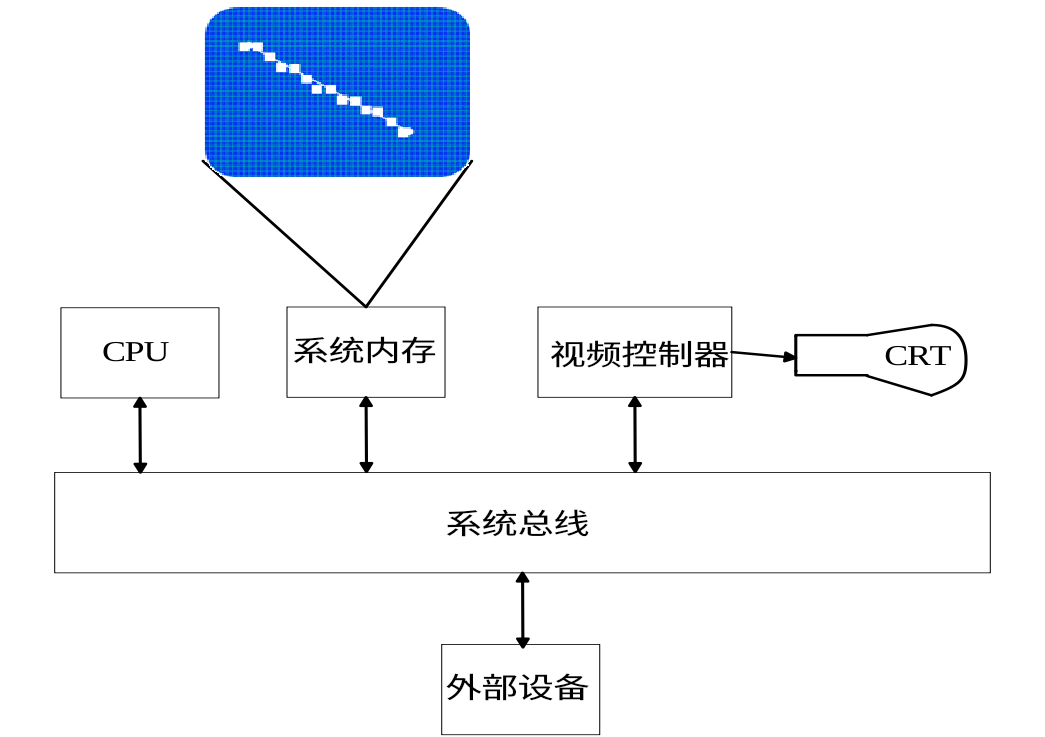
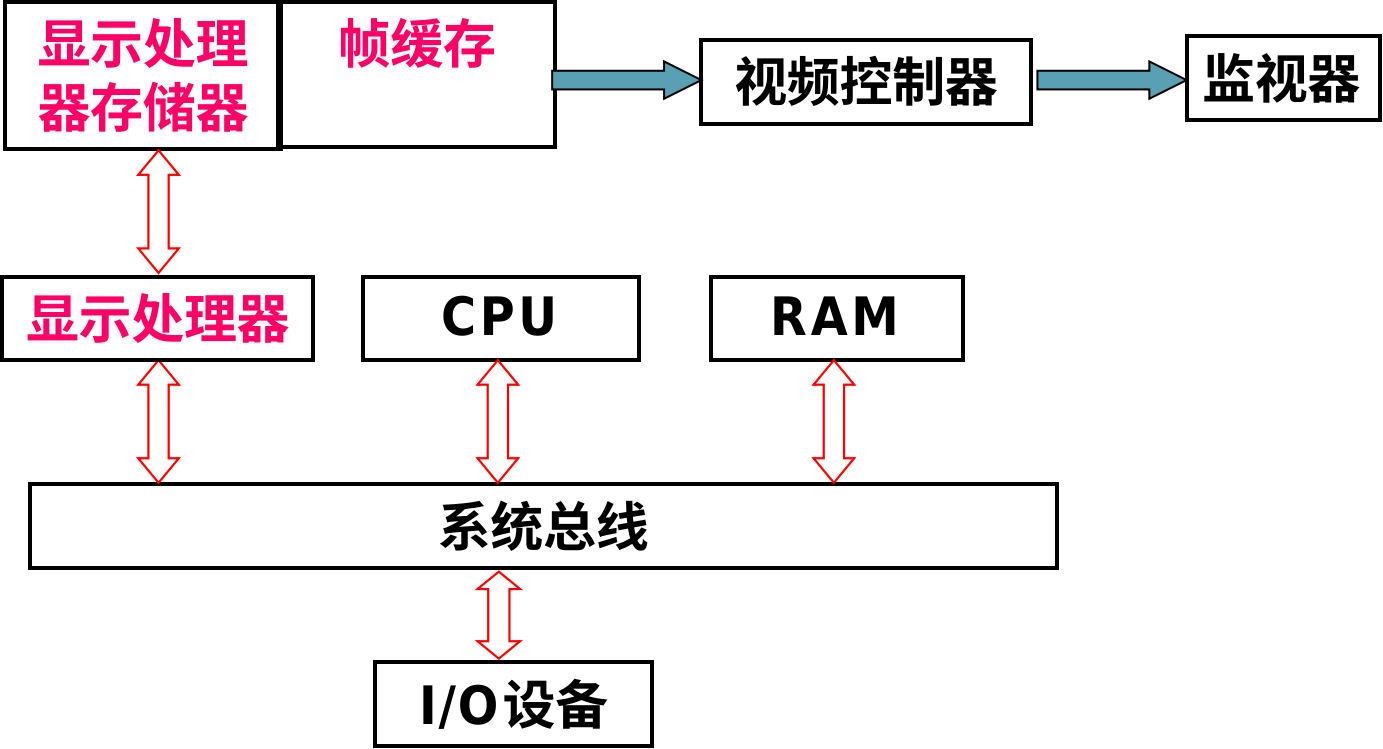
简述光栅式扫描显示系统
光栅扫描显示系统通过电子束(在CRT中)或像素寻址(在现代显示器中)按特定的顺序扫描屏幕,将离散的像素点点亮,从而组成一幅完整的图像。
扫描过程:水平扫描 - 水平归位 - 垂直扫描 - 垂直归位(扫完一帧)
帧缓存:一块专门的内存区域,也就是显存,屏幕上每个像素的颜色值都存储在帧缓存对应的地址中。视频控制器不断地从帧缓存中读取数据,并将其转换为模拟信号(或数字信号)控制显示器的亮度/颜色
分辨率三种描述,扫描频率,带宽计算
屏幕分辨率 (Screen Resolution / Addressable Resolution):
- 定义: 显示系统能够区分(寻址)出的像素点的数量。通常用“水平像素数 $\times$ 垂直像素数”表示。
- 例子: $1920 \times 1080$, $1024 \times 768$。
- 意义: 决定了软件逻辑上生成的图像大小。
显示分辨率 (Physical Resolution / Dot Pitch):
- 定义: 显示器硬件本身能够显示的最高精细度。这取决于荧光粉点(CRT)或液晶单元(LCD)的物理间距。
- 指标: 通常用 点距 (Dot Pitch) 来描述,单位是毫米(mm)。点距越小,图像越细腻。
- 意义: 这是硬件的物理极限。如果屏幕分辨率超过了显示分辨率,图像会变
- 还有一个叫 dpi,每英寸点数。
行频(水平扫描频率 khz),帧频(也称垂直扫描频率,每秒钟重复绘制显示画面的次数 hz)
带宽 = 分辨率 * 刷新率 * 颜色深度
bresenham 算法(光栅化)
当斜率大于 0 小于 1(另外的情况反转 xy 即可):
$\Delta x = x_2 - x_1$
$\Delta y = y_2 - y_1$
$C_1 = 2\Delta y$ (当 $p_k < 0$ 时的增量)
$C_2 = 2\Delta y - 2\Delta x$ (当 $p_k \ge 0$ 时的增量)
定起点: 画下第一个点 $(x_0, y_0)$。
算初值: 计算第一个“裁判数” $p_0$。
循环走: x 每次 +1,然后看当前的 $p$:
- 如果 $p < 0$:y 不动,更新 $p = p + C_1$ 。
- 如果 $p \ge 0$:y +1,更新 $p + C_2$ 。
重复: 直到走到终点。
(中点画线算法)
假设我们要画一条斜率 $k$ 在 $0$ 到 $1$ 之间的直线(比较平缓的线)。 当我们已经画好了当前的点 $(x_i, y_i)$,下一步我们要决定下一个点画在哪。在这个两个备选点的中间取一个点,叫做中点 $M$。 坐标是:$M = (x_i + 1, y_i + 0.5)$
如果红线在中点上方: 说明真实的线更靠上,我们应该选择上面的那个点 (NE),即 $(x+1, y+1)$。
如果红线在中点下方: 说明真实的线更靠下,我们应该选择下面的那个点 (E),即 $(x+1, y)$
Bresenham 画圆
同理:选取(0,R)点,下一步(x+1)不是在右垂直,就是往下面。
引入决策参数:
$$d_0 = 3 - 2R$$循环走: x 每次 +1,然后看当前的 $d$:
- 如果 $d < 0$:y 不动,更新 $d = d + 4x_k + 6$ 。
- 如果 $d \ge 0$:y +1,更新 $d = d + 4(x_k - y_k) + 10$ 。
当 x > y 就停止。
描述扫描线多边形填充算法流程
建立边表 (ET):将所有边按其下端点的 $y$ 坐标分类存储。每条边记录 $(y_{max}, x, 1/k)$。
ET 数据结构 belike:
$$[ y_{max} \ |\ x \ |\ \Delta x ] \rightarrow \text{next}$$AET:一个链表,其中按照 x 从小到大排序
注意:如果两条边相交,把高度低的边向下移动,防止出现异常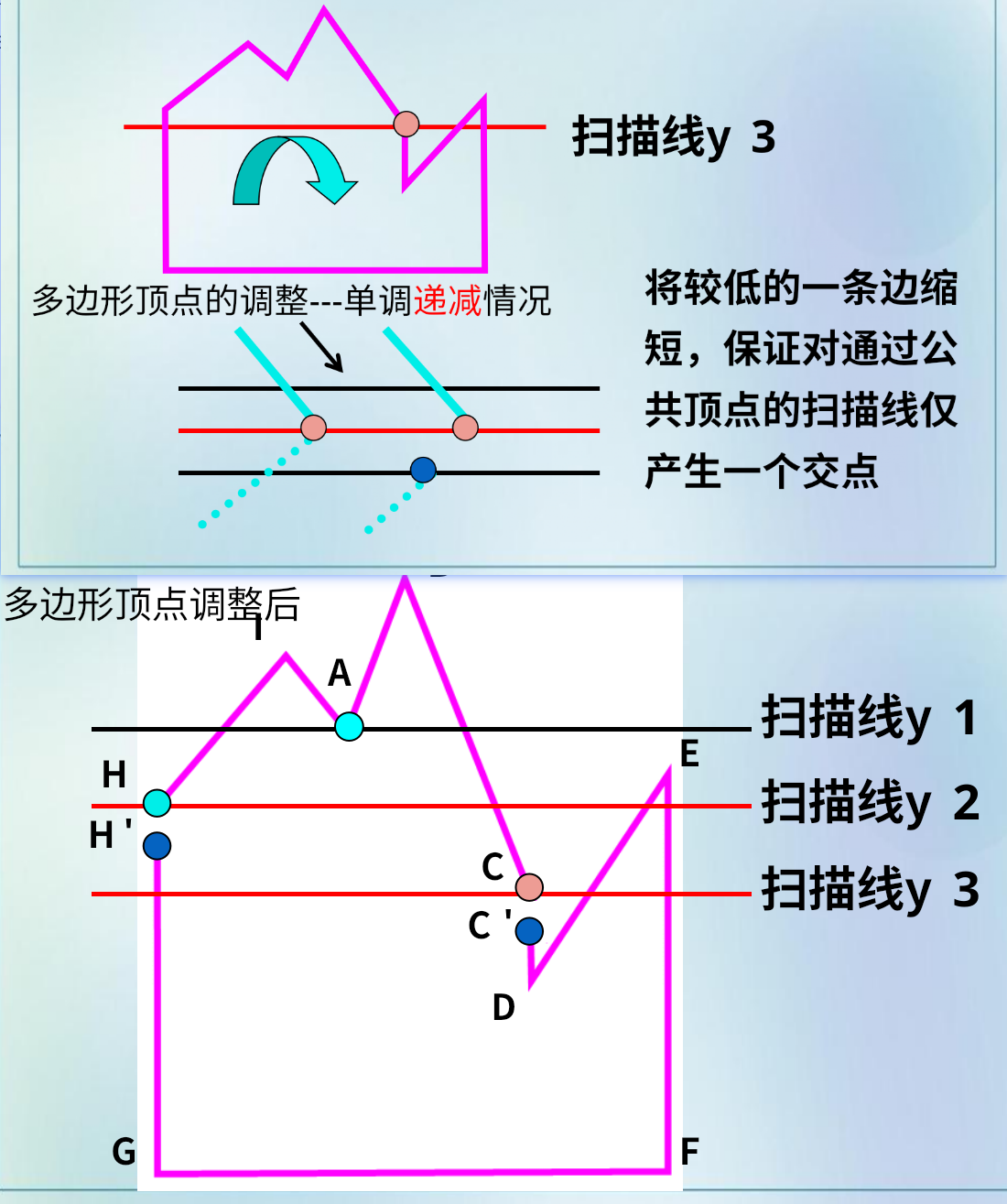
初始化:置扫描线 $y$ 为最低点的 $y$ 值,置活性边表 (AET) 为空。
循环扫描(直到 AET 为空且 ET 为空):
- 求交:将 ET 中当前 $y$ 行的新边加入 AET。
- 排序:将 AET 中的边按 $x$ 坐标递增排序。
- 配对填充:对 AET 中的边两两配对,填充每对边之间的像素区间。
- 清理:从 AET 中移除 $y_{max} = y$ 的边(已处理完的边)。(下闭上开原则)
- 上移:将 AET 中所有边的 $x$ 更新为 $x + 1/k$,并将扫描线 $y$ 加 1。
奇偶规则和非零环绕规则判断下列内外区域
奇偶规则:从测试点 $P$ 发射一条射线。统计射线与多边形所有边的交点个数。奇数为内,偶数为外。
非零环绕:
从测试点 $P$ 发射一条射线。
初始化环绕数 (Winding Number) = 0。
观察每一个与射线相交的边,看它的走向(相对于射线):
- 如果边是从右向左(或从下往上)穿过射线 $\rightarrow$ 环绕数 +1。
- 如果边是从左向右(或从上往下)穿过射线 $\rightarrow$ 环绕数 -1。
- (注:具体加减取决于坐标系定义,关键是一个方向加,相反方向减)
判断:
- 结果 $\neq 0$ $\rightarrow$ 内部 (Inside)
- 结果 $= 0$ $\rightarrow$ 外部 (Outside)
矩阵变换
一、 二维变换 (2D Transformations)
在 2D 中,我们使用 3x3 矩阵。
- 平移 (Translation)
要把点 $(x, y)$ 移动到 $(x+tx, y+ty)$:
$$\begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{bmatrix}$$(注:$t_x, t_y$ 放在最后一列。)
- 缩放 (Scaling)
要把物体沿 x 轴放大 $s_x$ 倍,沿 y 轴放大 $s_y$ 倍:
$$\begin{bmatrix} s_x & 0 & 0 \\ 0 & s_y & 0 \\ 0 & 0 & 1 \end{bmatrix}$$(注:缩放系数在对角线上。)
- 旋转 (Rotation)
绕原点逆时针旋转 $\theta$ 角:
$$\begin{bmatrix} \cos\theta & -\sin\theta & 0 \\ \sin\theta & \cos\theta & 0 \\ 0 & 0 & 1 \end{bmatrix}$$(注:这是最容易记混的。记住:主对角线是 cos,副对角线是 sin,且第一行有个负号。)
二、 三维变换 (3D Transformations)
在 3D 中,我们使用 4x4 矩阵。这是现代图形 API(如 OpenGL/WebGL)通用的标准。
$$\begin{bmatrix} 1 & 0 & 0 & t_x \\ 0 & 1 & 0 & t_y \\ 0 & 0 & 1 & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix}$$
- 平移 (Translation)
$$\begin{bmatrix} s_x & 0 & 0 & 0 \\ 0 & s_y & 0 & 0 \\ 0 & 0 & s_z & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$$
- 缩放 (Scaling)
- 旋转 (Rotation) —— 复杂但必考
3D 旋转通常分解为绕 X、Y、Z 三个主轴的旋转(欧拉角)。
绕 Z 轴旋转 (Rotate Z) —— 就像在 2D 平面上转:
$$R_z(\theta) = \begin{bmatrix} \cos\theta & -\sin\theta & 0 & 0 \\ \sin\theta & \cos\theta & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$$绕 X 轴旋转 (Rotate X) —— X 坐标不变:
$$R_x(\theta) = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & \cos\theta & -\sin\theta & 0 \\ 0 & \sin\theta & \cos\theta & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$$绕 Y 轴旋转 (Rotate Y) —— 注意负号的位置!(这是个坑点):
$$R_y(\theta) = \begin{bmatrix} \cos\theta & 0 & \sin\theta & 0 \\ 0 & 1 & 0 & 0 \\ -\sin\theta & 0 & \cos\theta & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$$组合举例:先把物体放大 2 倍,再向前移动 10 米,再旋转 30 度。
你不需要分三步算坐标,而是算出三个矩阵 $S, T, R$,然后相乘:
$$M_{total} = R \cdot T \cdot S$$(注意顺序:通常是从右向左乘,即 $S$ 最先作用于顶点 $v$,写在最右边:$M \cdot v = R(T(S \cdot v))$)
二维:
针对固定点旋转:先移动到固定点(把固定点变成原点)然后照原点旋转,再移动回去。
沿指定方向缩放:旋转到指定方向(把指定方向变成坐标轴)然后照坐标轴方向放缩,再旋转回去
三维:
绕特定轴旋转:先把原点搬到轴经过的点,再绕 X 轴旋转 $\alpha$ 角,让轴位于 XZ 平面上。再绕 Y 轴旋转 $\beta$ 角,让轴和 Z 轴重合。最后进行旋转,绕 Z 轴旋转,然后一步一步还原。
坐标系变换:计算 $n, u, v$ 轴,当世界 -> 局部(改变摄像机)时,构造矩阵 M = R T,R = $\begin{bmatrix} & \overrightarrow{u} & & 0 \ & \overrightarrow{v} && 0\& \overrightarrow{n} && 0 \ 0 & 0 & 0 & 1 \end{bmatrix}$,当局部 -> 世界,M中uvn 要竖着放,且直接把位置放进去作为第四列:
$$M_{Model} = \begin{bmatrix} u_x & v_x & n_x & Q_x \\ u_y & v_y & n_y & Q_y \\ u_z & v_z & n_z & Q_z \\ 0 & 0 & 0 & 1 \end{bmatrix}$$)然后对所有的点应用变化 M.
$$n = \text{normalize}(Eye - Target)$$$$w = \cos(\frac{\theta}{2})$$$$x = n_x \cdot \sin(\frac{\theta}{2})$$$$y = n_y \cdot \sin(\frac{\theta}{2})$$$$z = n_z \cdot \sin(\frac{\theta}{2})$$在标准的右手坐标系(如 OpenGL)中,摄像机是看向 -Z 轴的。这意味着 +Z 轴(也就是 $n$)必须指向摄像机的背后
$$u = \text{normalize}(Up_{world} \times n)$$$n \times u = v$
描述观察变换的坐标变换关系
观察变换是将物体顶点从世界坐标系转换到观察坐标系(摄像机坐标系)的过程。
这一变换关系可以通过构建一个UVN 坐标系来实现,具体分为两步:
-
平移变换:将世界原点平移至摄像机的视点位置(实际上是将摄像机移回原点),使视点重合于 $(0,0,0)$。
-
旋转变换:将世界坐标轴旋转对齐到摄像机的 UVN 轴(右向量、上向量、视线反向向量),使摄像机光轴指向 -Z 方向,上方指向 +Y 方向。
最终变换矩阵为旋转矩阵与平移矩阵的乘积:$M_{view} = R \cdot T$。
窗口映射
10,已知w1=10, w2=20, w3=40, w4=80,
v1=-10, v2=20, v3=10, v4=120,
窗口中一点P(15,60),求视口中的映射点P'
$$\frac{x - x_{wmin}}{x_{wmax} - x_{wmin}} = \frac{x' - x_{vmin}}{x_{vmax} - x_{vmin}}$$$$\frac{y - y_{wmin}}{y_{wmax} - y_{wmin}} = \frac{y' - y_{vmin}}{y_{vmax} - y_{vmin}}$$CS 算法(线段裁剪)
步骤 1:区域编码 (Encoding)
编码规则通常为 TBRL (Top, Bottom, Right, Left) 4位二进制:
- 位 1 (Left): $x < x_{min}$
- 位 2 (Right): $x > x_{max}$
- 位 3 (Bottom): $y < y_{min}$
- 位 4 (Top): $y > y_{max}$
步骤 2:逻辑判断
- 可见性测试:
Code1 | Code2 = 1001 != 0。说明线段不完全在内部。 - 完全拒绝测试:
Code1 & Code2 = 0000。说明线段不是完全在外部(有可能穿过窗口)。 - 结论: 需要求交点进行裁剪。
步骤 3:求交点 (Clipping)
第 1 轮:处理 $P_1$ (Code = 0001, 左侧越界)
我们需要求线段与 左边界 $x = -1$ 的交点。
公式:$y = y_1 + m(x_{min} - x_1)$
$$y = \frac{1}{6} + \frac{2}{3}(-1 - (-1.5))$$$$y = \frac{1}{6} + \frac{2}{3}(0.5) = \frac{1}{6} + \frac{1}{3} = \frac{3}{6} = 0.5$$- 算出新交点 $P_1’(-1, 0.5)$。
- $P_1’$ 的新编码为 0000 (在窗口内)。
第 2 轮:处理 $P_2$ (Code = 1000, 上侧越界)
我们需要求线段与 上边界 $y = 1$ 的交点。
公式:$x = x_2 + \frac{1}{m}(y_{max} - y_2)$
$$x = 0.5 + \frac{3}{2}(1 - 1.5)$$$$x = 0.5 + 1.5(-0.5) = 0.5 - 0.75 = -0.25$$- 算出新交点 $P_2’(-0.25, 1)$。
- $P_2’$ 的新编码为 0000 (在窗口内)。
编码都为 0000,所以结束。可能还要多次求交点。
LB 算法
核心思想: 将线段表示为参数方程 $P(t) = P_1 + t(P_2 - P_1)$,利用不等式一次性求出线段在窗口内的 $t$ 值范围 $(u_1, u_2)$。
步骤 1:计算参数 $\Delta x, \Delta y$
步骤 2:计算 $p_k, q_k$
根据不等式 $p_k \cdot t \le q_k$,列出 4 个方向的参数
| k | 边界方向 | 不等式 | pk (方向分量) | qk (距离分量) | 几何意义 (q/p) |
|---|---|---|---|---|---|
| 1 | 左 (Left) | $x_{min} \le x$ | $-\Delta x$ | $x_1 - x_{min}$ | 线段延长线与左边界交点的 t |
| 2 | 右 (Right) | $x \le x_{max}$ | $\Delta x$ | $x_{max} - x_1$ | 线段延长线与右边界交点的 t |
| 3 | 下 (Bottom) | $y_{min} \le y$ | $-\Delta y$ | $y_1 - y_{min}$ | 线段延长线与下边界交点的 t |
| 4 | 上 (Top) | $y \le y_{max}$ | $\Delta y$ | $y_{max} - y_1$ | 线段延长线与上边界交点的 t |
步骤 3:求解 $u_{min}$ (入点) 和 $u_{max}$ (出点)
初始化:$u_{1} = 0$ (起点), $u_{2} = 1$ (终点)。
- 当 $p_k < 0$ 时(从外向里穿,更新 $u_1$): 取 $\max(u_1, q_k/p_k)$
- 当 $p_k > 0$ 时(从里向外穿,更新 $u_2$): 取 $\min(u_2, q_k/p_k)$
步骤 4:检查并计算最终坐标。带入更新后的 u1,u2。要求 u1 < u2 才有效。
(NLN直线剪裁)
(Sutherland-Hodgman 算法 )
(3D裁剪)
投影
投影三要素:投影中心、投影平面、投影射线。
投影分为透视投影、平行投影
平行投影:投影中心距离所观察的对象无穷远,投影线互相平行
- 视景体 (View Volume): 是一个长方体 (Rectangular Box)。
透视投影:投影射线汇聚到投影中心。有远小近大的效应。
-
灭点 (Vanishing Point): 空间中平行的线(如铁轨),在投影后会汇聚消失在地平线上的某一点。
-
主灭点是场景中与主坐标轴(X轴、Y轴、Z轴)平行的直线组,在投影面上汇聚的点。
-
视景体 (View Volume): 是一个棱台 (Frustum)(像一个被切掉尖顶的金字塔)。
-
一点透视: 有 1 个灭点(正对着看走廊)。
两点透视: 有 2 个灭点(站在街道转角看建筑)。
三点透视: 有 3 个灭点(仰视摩天大楼)。
观察体调整
“观察体调整”这个词听起来很晦涩,但在图形学考纲里,它对应的是一个非常核心的概念:规范化观察体 (Normalization of View Volume)。
简单来说,它的核心任务就是:把形状各异的摄像机视野,变成一个标准的正方体盒子。
这通常发生在投影变换 (Projection Transformation) 这一步。我将分三个层次为你拆解这个知识点:
- 什么是“观察体” (View Volume)?
观察体就是摄像机能“看到”的三维空间区域。只有在这个区域里的物体才会被画出来,外面的会被裁剪掉。
- 平行投影的观察体是:一个长方体 (Box)。
- 透视投影的观察体是:一个棱台 (Frustum,像被砍了尖的金字塔)。
- 为什么要“调整”它?(核心考点)
想象一下,透视投影的观察体是一个梯形棱台。
如果要在这个棱台里做裁剪(判断物体是否在视野内),数学运算非常麻烦:
- 你需要计算物体是否在 6 个倾斜的平面之间。
- 平面方程都很复杂(比如 $x < z$ 或 $y < z * \tan(\theta)$)。
为了偷懒(提高效率),图形学想出了一个绝招:
不要直接在棱台里裁剪,而是先把这个棱台“捏”成一个标准的正方体。
这个正方体被称为 规范化观察体 (Canonical View Volume, CVV)。
- 范围通常是:$x, y, z \in [-1, 1]$。
- 是一个边长为 2 的正方体,中心在原点。
- “调整”的过程是怎么样的?
所谓“观察体调整”,本质上就是构造一个投影矩阵,把世界坐标系里的棱台,变换成裁剪坐标系里的正方体。
这个过程根据投影方式不同分为两种:
A. 平行投影的调整
- 操作: 平移 + 缩放。
- 过程:
- 把长方体的中心移到原点 $(0,0,0)$。
- 把它拉伸或压缩,直到长宽高都变成 2(即范围 -1 到 1)。
- 矩阵: 比较简单,只有缩放和平移分量。
B. 透视投影的调整 (重点/难点)
- 操作: 变形 (Distortion)。
- 过程:
- 把棱台的远平面缩小,近平面保持(或者按比例缩放),硬生生把它“掰”成一个长方体。
- 这一步会导致物体发生“近大远小”的变形(这就是透视的来源!)。
- 变换后,原来的棱台变成了 CVV 正方体。
- 结果: 之后我们只需要判断 $x, y, z$ 是否在 $[-1, 1]$ 之间,就可以轻松完成裁剪了。
多边形网格模型表示
基本数据表形式:顶点表、多边形面表(关联边)、边表(关联顶点)。
翼边数据结构:每条边存储的信息1)该边的顶点(指定其起点和终点);2)沿着起点走到终点时的左边面和右边面;3)对其左边面,该边的前驱和后继边;4)对其右边面,该边的前驱和后继边。
半边数据结构:记录重点、下一半边、对半边、隶属的面
用函数描述的二个次曲面模型,如球体表面,如何进行绘制
多边形逼近:
参数方程法
双重循环: 写两个 for 循环,将 $\theta$ (经度) 和 $\phi$ (纬度) 按固定步长(比如每 10 度一步)进行离散化。
计算顶点: 代入公式算出每个 $(u, v)$ 对应的 $(x, y, z)$ 坐标。
连接网格: 将相邻的四个点 $(i, j), (i+1, j), (i, j+1), (i+1, j+1)$ 连接成两个三角形。
结果: 你会得到一个看起来像足球或者地球仪网格的模型。切分得越细,看起来越圆。
隐式方程法
有些曲面很难写出参数方程,只知道 $f(x,y,z) = 0$(例如球:$x^2 + y^2 + z^2 - R^2 = 0$)。
- 算法:行军立方体算法 (Marching Cubes)
- 绘制步骤:
- 把空间划分成无数个小格子(体素)。
- 检测每个格子的 8 个角点是在球内还是球外(代入方程看正负)。
- 如果有的点在内、有的在外,说明曲面穿过了这个格子。
- 查表生成对应的三角形面片来近似曲面。
(超二次曲面)
通过将额外的参数插入二次方程而形成,从而便于调整物体的形状.增加的参数数目等同于物体的维数:为曲线增加一个参数,而对于曲面,则增加两个参数.
$\left(\frac{x}{a}\right)^2 + \left(\frac{y}{b}\right)^2 + \left(\frac{z}{c}\right)^2 = 1$
$\left[ \left|\frac{x}{a}\right|^{2/\epsilon_2} + \left|\frac{y}{b}\right|^{2/\epsilon_2} \right]^{\epsilon_2/\epsilon_1} + \left|\frac{z}{c}\right|^{2/\epsilon_1} = 1$
样条曲线,样条曲面
样条曲线:通过一组指定点集而生成平滑曲线的柔性带。
(由多项式曲线段连接而成的曲线,在每段的边界处满足特定的连续性条件)
样条曲面:使用两组正交样条曲线进行描述
样条曲线的类型
插值样条曲线:选取的多项式使得曲线通过每个控制点
例子:三次样条插值、自然三次样条插值、Hermite样条插值、Cardinal样条插值、Kochanek_Bartels样条插值
逼近样条曲线:选取的多项式不一定使曲线通过每个控制点
例子:Bezier曲线、B_样条曲线
凸壳
包含一组控制点的凸多边形边界
凸壳的作用:提供了曲线或曲面与包围控制点的区域之间的偏差的测量。以凸壳为界的样条保证了多项式沿控制点的平滑前进
分段连续中连续的定义
参数连续性条件 :两个相邻曲线段在相交处的参数导数相等
零阶连续(C0连续):简单地表示曲线连接
一阶连续(C1连续):说明代表两个相邻曲线的方程在相交点处有相同的一阶导数(切线)
二阶连续(C2连续):两个曲线段在交点处有相同的一阶和二阶导数,交点处的切向量变化率相等
贝塞尔曲线的特性
通过第一个和最后一个控制点。
在第一个控制点处与 P0P1 相切,在最后一个控制点与直线 Pn-1Pn 相切。
总是落在控制点的凸壳内。(保证曲线沿着控制点的平稳前进)
Bézier曲线和B样条曲线均不能精确表示除抛物线外的其他的圆锥曲线(如椭圆)(所以提出了 NURBS)
(细分网格技术)
(1)几何规则在现有的多边形网格基础上生成一系列的新顶点并计算其位置坐标的规则(通常都包含特定的平均化机制)(2)拓扑规则在边或面上插入新顶点,更新旧顶点以及各个顶点之间的连接关系的规则,也称网格分裂。
细分规则分类逼近型 vs. 插值型逼近型:新顶点位置由旧顶点加权平均计算,不保留原始顶点位置(如Catmull-Clark、Doo-Sabin、Loop)。插值型:保留原始顶点位置,仅新增顶点(如Butterfly算法)。适用网格类型任意拓扑网格:Catmull-Clark、Doo-Sabin、Butterfly(改进版)。三角形网格:Loop、Butterfly(原始版)、√3细分。四边形网格:Catmull-Clark。
(实体构造技术)
(空间分割)
(分形几何) & (NeRF) & (高斯泼溅)
VBO,PBO,FBO
顶点缓存对象、像素缓存对象、帧缓存对象
如何创建 VBO,并用它绘制
|
|
深度缓存的意义
在像素层级上解决了谁挡住谁的问题,完成了隐藏面消除/可见面确定,完成了可见面判断问题。
深度测试:
维护一个 Z-buffer,存储屏幕上每个像素点的深度信息
发生在光栅化之后,片元着色器运行之时
将表面对应像素的深度值与当前深度缓存中的值进行比较,如果大于等于深度缓存中的值,则深度测试不通过,不能绘制;若小于则更新该像素对应的深度值和颜色值
屏幕上的 Z 值,和实际距离 Z 不是成正比,而是和 实际距离的倒数 ($1/Z$) 成正比。
$$F_{depth} = \frac{1/z - 1/near}{1/far - 1/near}$$因此会发生 Z-fight 问题
描述固定管线中的光照模型
在计算机图形学的“固定管线”(Fixed Function Pipeline,即早期的 OpenGL 1.x/2.x 或 DirectX 9 之前)时代,光照模型是硬编码在显卡驱动和硬件里的。你不能像现在写 Shader 那样随意修改光照算法,只能通过设置参数(开/关灯、设置颜色、设置材质)来控制它。
固定管线使用的是一个经典的经验模型,通常被称为 Blinn-Phong 反射模型(或标准的 Phong 模型),并结合 Gouraud 着色(Gouraud Shading) 进行插值。
它的核心公式是:
$$最终颜色 = 自发光 + 环境光 + 漫反射 + 镜面反射$$下面详细拆解这四个部分:
- 四大组成部分
A. 自发光 (Emission)
- 概念: 模拟物体自己在发光(比如夜光表针)。
- 特点: 它只影响物体本身的颜色,不会照亮周围的物体(因为它不是光源)。
- 计算: 直接加上材质的自发光颜色。
- $$I_{emission} = Material_{emission}$$
B. 环境光 (Ambient)
- 概念: 模拟光线在场景中经过无数次反射后形成的“底色”。如果没有环境光,背光面将是一片死黑。
- 特点: 来自四面八方,没有方向,照亮物体的所有面,颜色均匀。
- 计算: 光源环境光颜色 $\times$ 材质环境光反射率。
- $$I_{ambient} = Light_{ambient} \times Material_{ambient}$$
C. 漫反射 (Diffuse) —— 最核心部分
- 概念: 模拟光线照射在粗糙表面(如墙壁、纸张)上向各个方向均匀散射的现象。
- 定律: 兰伯特定律 (Lambert’s Cosine Law)。光线越垂直于表面,表面越亮;光线越倾斜,表面越暗。
- 计算: 取决于 法线 (Normal, N) 和 光线方向 (Light Dir, L) 的夹角余弦值(即点积)。
- 如果光在背面(夹角 > 90度),结果取 0(不照亮)。
- $$I_{diffuse} = (L \cdot N) \times Light_{diffuse} \times Material_{diffuse}$$
D. 镜面反射 (Specular) —— 高光
- 概念: 模拟光线照射在光滑表面(如金属、镜子)上形成的刺眼亮斑。
- 特点: 只有当视线方向和反射光线方向非常接近时才能看到。
- 模型: 固定管线通常使用 Blinn-Phong 模型(因为它比标准 Phong 模型计算 反射向量 R 要快)。它计算 半程向量 (Half Vector, H) 与 法线 (N) 的夹角。
- $H$ 是光线方向 $L$ 和 视线方向 $V$ 的中间向量。
- 光泽度 (Shininess): 一个指数参数。指数越大,光斑越小越锐利(越像金属);指数越小,光斑越散(越像塑料)。
- $$I_{specular} = (N \cdot H)^{shininess} \times Light_{specular} \times Material_{specular}$$
- 光源类型 (Light Sources)
在固定管线中,你可以开启多个光源(通常限制为 8 个,
GL_LIGHT0~GL_LIGHT7),每种光源有不同的计算逻辑:
- 平行光 (Directional Light):
- 模拟太阳。没有位置,只有方向。光线互相平行,无衰减。
- 点光源 (Point Light):
模拟灯泡。有位置,光线向四面八方发散。
衰减 (Attenuation): 光强随距离减弱。固定管线使用二次衰减公式:
$$Attenuation = \frac{1}{K_c + K_l \cdot d + K_q \cdot d^2}$$(其中 $d$ 是距离,$K_c, K_l, K_q$ 是常数、线性、二次衰减系数)
- 聚光灯 (Spot Light):
- 模拟手电筒。有位置、方向、切光角 (Cutoff Angle) 和 聚焦指数 (Spot Exponent)。超出角度范围的地方没有光。
- 实现方式:顶点着色 (Gouraud Shading)
这是固定管线光照最显著的特征,也是它最大的缺陷。
- 什么时候算? 光照计算发生在 顶点处理阶段 (Vertex Processing)。
- 怎么算?
- 对三角形的 3 个顶点分别计算光照颜色(应用上面的公式)。
- 在光栅化阶段,利用三角形的重心坐标,将这 3 个顶点的颜色进行线性插值,填满整个三角形。
- 缺陷:
- 高光锯齿: 如果高光点正好落在三角形中间(不在顶点上),插值会导致高光消失或变形。
- 马赫带效应: 明暗交界处会有明显的棱角感。
- 要得到细腻的高光,必须极大地增加模型面数。
总结:固定管线光照公式
对于场景中的每一个顶点,显卡会自动套用以下公式(伪代码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17Color_Final = Material_Emission; // 自发光 for (each Light) { // 1. 计算衰减 float Attenuation = 1.0 / (Kc + Kl*d + Kq*d^2); // 2. 环境光 Color_Final += Light_Ambient * Material_Ambient * Attenuation; // 3. 漫反射 (Lambert) float DiffuseFactor = max(dot(N, L), 0.0); Color_Final += Light_Diffuse * Material_Diffuse * DiffuseFactor * Attenuation; // 4. 镜面反射 (Blinn-Phong) float SpecularFactor = pow(max(dot(N, H), 0.0), Material_Shininess); Color_Final += Light_Specular * Material_Specular * SpecularFactor * Attenuation; }这就是为什么以前的游戏看起来都有种“油腻腻的塑料感”或“棱角分明”的原因,因为它们都被限制在这个固定的数学模型里了。
实验题部分
three js 框架
|
|
实验题2
|
|
考试代码记忆指南 (如何写出关键部分)
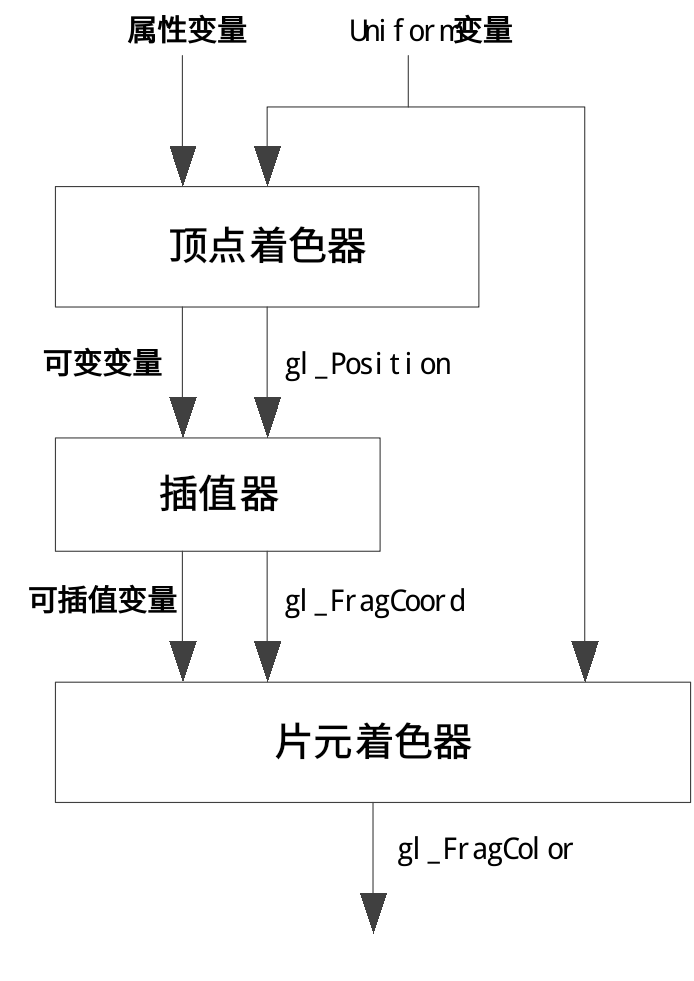
在考场上,JS 框架部分比较好写,难点在于 GLSL 代码。请记住以下口诀和逻辑:
- 顶点着色器 (Vertex Shader) 只需要做两件事
Three.js 会自动提供 position, normal, modelMatrix, viewMatrix, projectionMatrix 这些内置变量,你不需要声明。
- 算位置:
gl_Position = projectionMatrix * viewMatrix * modelMatrix * vec4(position, 1.0);(必写) - 传数据: 为了让片元着色器能算光照,必须把 “法线” 和 “世界坐标” 传过去。
vNormal = normalMatrix * normal;vWorldPosition = (modelMatrix * vec4(position, 1.0)).xyz;
- 片元着色器 (Fragment Shader) 背诵 Phong 公式
Phong 模型 = 环境光 + 漫反射 + 镜面反射。
- 准备向量: 记得所有的向量都要
normalize(归一化)。- $N$:
norm = normalize(vNormal) - $L$:
lightDir = normalize(uLightPos - vWorldPosition) - $V$:
viewDir = normalize(uViewPos - vWorldPosition) - $R$:
reflectDir = reflect(-lightDir, norm)(注意负号!)
- $N$:
- 算漫反射 (Diffuse):
- 公式:$L \cdot N$
- 代码:
diff = max(dot(lightDir, norm), 0.0)
- 算镜面反射 (Specular):
- 公式:$(V \cdot R)^{shininess}$
- 代码:
spec = pow(max(dot(viewDir, reflectDir), 0.0), uShininess)
- JS 部分的坑 (容易丢分的地方)
-
Uniforms 传值: 记得
uViewPos(相机位置) 必须在animate循环里实时更新:JavaScript
1material.uniforms.uViewPos.value.copy(camera.position);如果不更新,当你旋转场景时,高光会像贴图一样贴在物体上不动,这就被判错了。
如果考题变成 “Blinn-Phong”?
唯一的区别在于镜面反射的计算:
- Phong: 使用反射向量 $R$ 和视线 $V$ 的夹角。
- Blinn-Phong: 使用 半程向量 (Half Vector) $H$ 和法线 $N$ 的夹角。
代码修改:
OpenGL Shading Language
|
|
Blinn-Phong 的计算量比 Phong 小(不用算 reflect),且效果更柔和,是现代图形学的默认选择,但题目如果点名 Phong,请务必使用 reflect。
js部分:
第一步:搭摄影棚 (环境三件套)
不管做什么 Three.js 程序,这三行代码是雷打不动的。
- Scene (场景): 这一步就是清场,准备一个黑漆漆的空间。
- Camera (摄像机): 决定观众从哪里看。
- Renderer (渲染器): 负责把画面画到网页上。
代码模板 (背诵版):
JavaScript
|
|
第二步:准备剧本和道具 (ShaderMaterial) —— 考试核心
这是实验题最关键的一步。普通材质只需要设颜色,但 ShaderMaterial (着色器材质) 需要你手动传数据给显卡。
你需要构建一个 “数据桥梁” (Uniforms)。
- JS (CPU) 里的数据通过
uniforms传给 Shader (GPU)。 - 写法规则:
变量名: { value: 具体的值 }(注意那个.value是死格式)。
代码逻辑:
JavaScript
|
|
第三步:演员就位 (Mesh)
在 Three.js 里,一个物体 (Mesh) = 骨架 (Geometry) + 皮肤 (Material)。
代码逻辑:
JavaScript
|
|
第四步:开机拍摄 (主循环)
这一步是为了让画面动起来,并且实时更新数据。
代码逻辑:
JavaScript
|
|
总结:JS 部分你需要记什么?
如果考试让你手写,或者填空,重点关注这几个变量名和属性:
- 对象创建:
new THREE.Scene(),new THREE.PerspectiveCamera(...),new THREE.WebGLRenderer()。 - 材质核心:
new THREE.ShaderMaterial({...})里面有三个关键属性:uniforms,vertexShader,fragmentShader。 - 数据传输: 记住
uniforms里的格式永远是{ value: ... }。 - 添加到场景:
scene.add(mesh)。 - 渲染循环:
requestAnimationFrame和renderer.render。